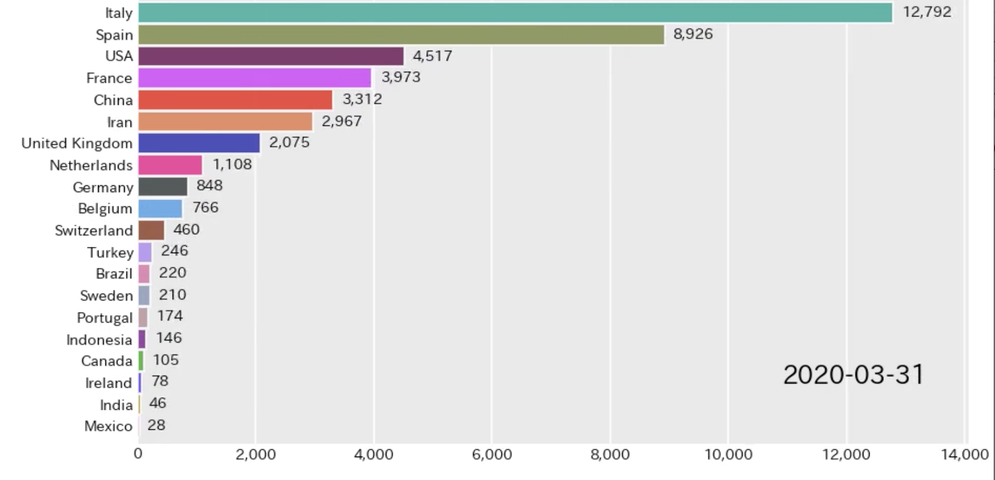
今回はPandas_Datareaderを使って
日本の株価を取得して分析する方法についてです。
解説動画はこちら
始めに
最近、日本の株価がバブル期並みの
高音を付けている様です。
この際
Pythonで株価のデータ分析が行える様に
なってみるのも面白いかと思います。
日本の株価を取得するには
pandas_datareaderというものを使います。
Google Colabであれば
最初から使えるので、こちらを使っていきましょう。
pandas_datareader
様々な金融商品のデータを取得する事ができます
その中でも、日本の株価は「stooq」というもので
ポーランドかどこかの会社のデータの様です。
こちらを取得して分析を始めていきましょう。
基本的な使い方はこのようになっています。
銘柄コードを指定して取得します。
データを取得するコードはこちら
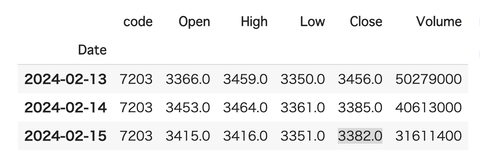
銘柄を変えたい場合は
codeの数字を変えて下さい。
株価から指標を計算してみる
ここからは取得したデータを使って
株価の分析に必要な指標を計算していきます。
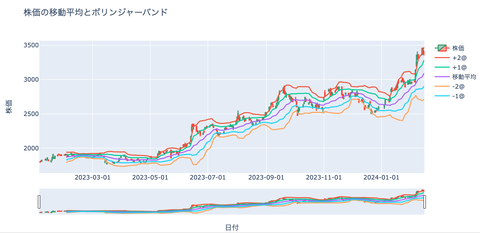
移動平均
過去X日間の価格の平均値です
通常は終値を使います。
ボリンジャーバンド
+-1-3@までが一般的に良く用いられます。
@は標準偏差の様な意味合いです。
移動平均などの指標の計算
指標が計算できたら描画してみましょう。
描画には「Plotly」を用います。
これはライブで操作が出来る描画ライブラリで
静止画ではないので、色々な操作が行え捗ります。
ここからはテクニカル指標を
計算して描画していきましょう。
日本の株価を取得して分析する方法についてです。
解説動画はこちら
始めに
最近、日本の株価がバブル期並みの
高音を付けている様です。
この際
Pythonで株価のデータ分析が行える様に
なってみるのも面白いかと思います。
日本の株価を取得するには
pandas_datareaderというものを使います。
Google Colabであれば
最初から使えるので、こちらを使っていきましょう。
pandas_datareader
様々な金融商品のデータを取得する事ができます
その中でも、日本の株価は「stooq」というもので
ポーランドかどこかの会社のデータの様です。
こちらを取得して分析を始めていきましょう。
基本的な使い方はこのようになっています。
import pandas_datareader.data as web web.DataReader(銘柄コード, data_source='stooq', start=開始日,end=終了日)株価は銘柄ごとのデータになっているので
銘柄コードを指定して取得します。
データを取得するコードはこちら
# ライブラリのインポート import os import datetime as dt import pandas_datareader.data as web import plotly.graph_objects as go import pandas as pd # 銘柄コード入力(7203はトヨタ自動車) code = "7203" symbol = code + ".JP" # 2023-01-01以降の株価取得 start , end = '2023-01-01', dt.date.today() #データ取得 df = web.DataReader(symbol, data_source='stooq', start=start,end=end) df.insert(0, "code", code, allow_duplicates=False) df = df.sort_index() df.tail(3)
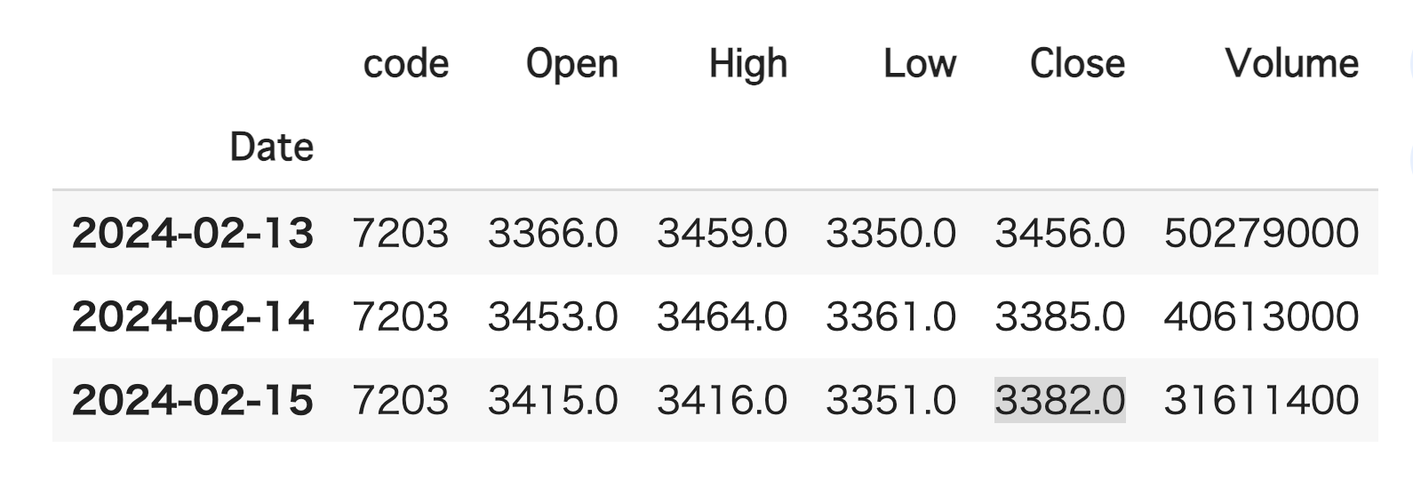
銘柄を変えたい場合は
codeの数字を変えて下さい。
株価から指標を計算してみる
ここからは取得したデータを使って
株価の分析に必要な指標を計算していきます。
移動平均
過去X日間の価格の平均値です
通常は終値を使います。
ボリンジャーバンド
移動平均を表す線と
その上下に値動きの幅を示す線を加えた指標で
その上下に値動きの幅を示す線を加えた指標で
「価格の大半がこの帯(バンド)の中に収まる」という
統計学を応用したテクニカル指標のひとつです。
+-1-3@までが一般的に良く用いられます。
@は標準偏差の様な意味合いです。
移動平均などの指標の計算
# 移動平均を計算する期間
period = 20
# 移動平均を計算
df[f'MA{period}'] = df['Close'].rolling(window=period).mean()
# ボリンジャーバンドを計算
std = df['Close'].rolling(window=period).std()
df['Upper Band1'] = df[f'MA{period}'] + 1 * std
df['Upper Band2'] = df[f'MA{period}'] + 2 * std
df['Upper Band3'] = df[f'MA{period}'] + 3 * std
df['Lower Band1'] = df[f'MA{period}'] - 1 * std
df['Lower Band2'] = df[f'MA{period}'] - 2 * std
df['Lower Band3'] = df[f'MA{period}'] - 3 * std
指標が計算できたら描画してみましょう。
描画には「Plotly」を用います。
これはライブで操作が出来る描画ライブラリで
静止画ではないので、色々な操作が行え捗ります。
# プロット用のデータを作成
data = [
go.Candlestick(
x=df.index,
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'],
name='株価',
),
go.Scatter(x=df.index,y=df['Upper Band2'],mode='lines',name='+2@',),
go.Scatter(x=df.index,y=df['Upper Band1'],mode='lines',name='+1@',),
go.Scatter(x=df.index,y=df[f'MA{period}'],mode='lines',name='移動平均',),
go.Scatter(x=df.index,y=df['Lower Band2'],mode='lines',name='-2@',),
go.Scatter(x=df.index,y=df['Lower Band1'],mode='lines',name='-1@',),
]
# レイアウト設定
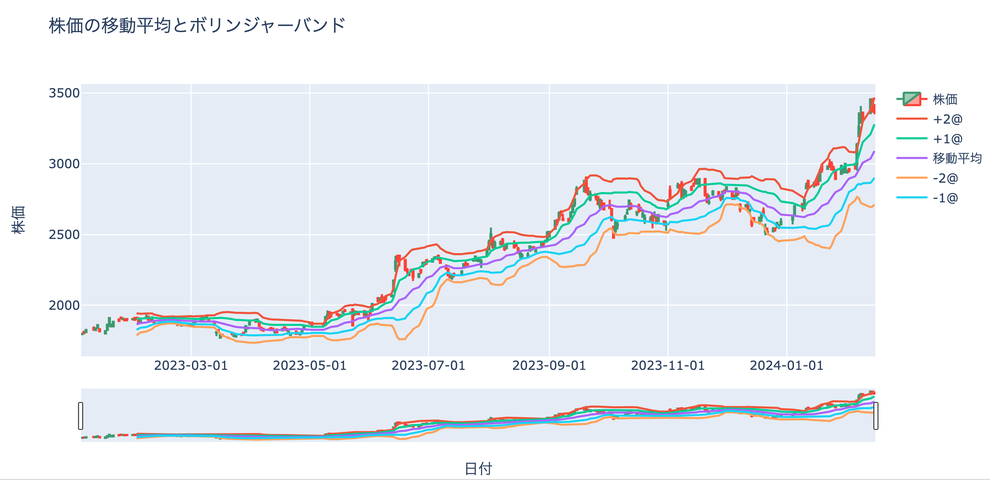
layout = go.Layout(
title='株価の移動平均とボリンジャーバンド',
xaxis=dict(
title='日付',
tickformat='%Y-%m-%d'
),
yaxis=dict(title='株価'),
)
# グラフを描画
fig = go.Figure(data=data, layout=layout)
fig.show()
ここからはテクニカル指標を
計算して描画していきましょう。
# RSIを計算する関数
def calculate_rsi(data, window=14):
delta = data.diff()
up = delta.copy()
down = delta.copy()
up[up < 0] = 0
down[down > 0] = 0
avg_gain = up.rolling(window).mean()
avg_loss = abs(down.rolling(window).mean())
rs = avg_gain / avg_loss
rsi = 100 - (100 / (1 + rs))
return rsi
# ストキャスティクスを計算する関数
def calculate_stochastic_oscillator(data, window=14):
lowest_low = data.rolling(window).min()
highest_high = data.rolling(window).max()
stochastic_oscillator = (data - lowest_low) / (highest_high - lowest_low) * 100
return stochastic_oscillator
# MACDを計算する関数
def calculate_macd(data, short_window=12, long_window=26, signal_window=9):
short_ema = data.ewm(span=short_window, adjust=False).mean()
long_ema = data.ewm(span=long_window, adjust=False).mean()
macd = short_ema - long_ema
signal_line = macd.ewm(span=signal_window, adjust=False).mean()
histogram = macd - signal_line
return macd, signal_line, histogram
# RSIを計算
df['RSI'] = calculate_rsi(df['Close'])
# ストキャスティクスを計算
df['%K'] = calculate_stochastic_oscillator(df['Close'])
df['%D'] = df['%K'].rolling(3).mean()
# MACDを計算
macd, signal_line, histogram = calculate_macd(df['Close'])
df['MACD'] = macd
df['Signal'] = signal_line
df['Histogram'] = histogram
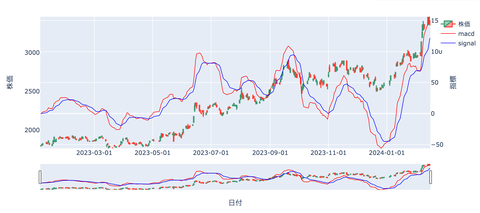
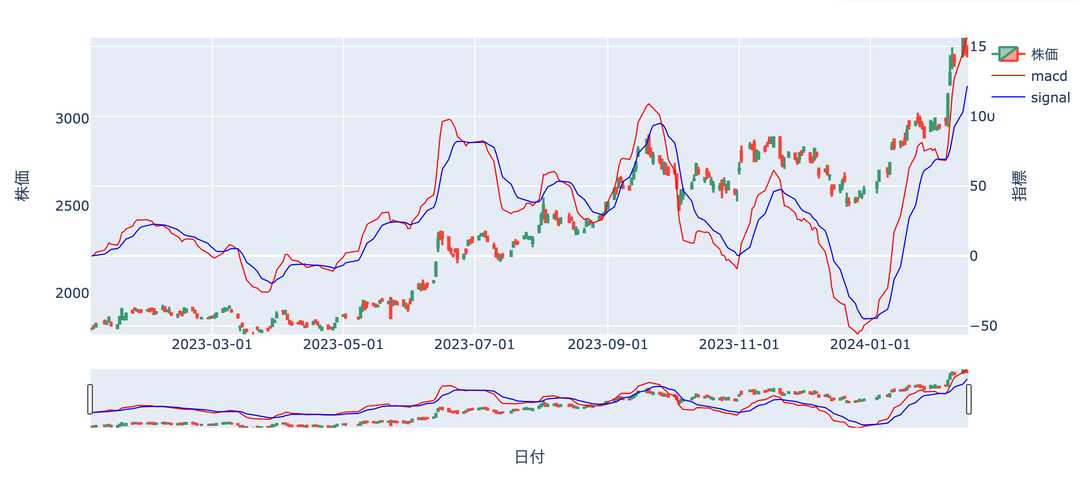
MACD(移動平均収束拡散手法)
短期の移動平均線と中長期の移動平均線を使用することで
買いと売りを判断する手法です。
MACDは基本となる線(MACD線)
MACDの移動平均線である
シグナル線の推移でマーケットを判断
シグナル線の推移でマーケットを判断
MACD線がシグナル線を上抜けると
ゴールデンクロス(買いタイミング)
ゴールデンクロス(買いタイミング)
MACD線がシグナル線を下抜けると
デッドクロス(売りタイミング)
デッドクロス(売りタイミング)
# MACD
fig = go.Figure(
data=[
go.Candlestick(
x=df.index,
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'],
name='株価',
yaxis='y1'
),
go.Scatter(x=df.index, y=df['MACD'], line=dict(color='red', width=1), name="macd", yaxis='y2'),
go.Scatter(x=df.index, y=df['Signal'], line=dict(color='blue', width=1), name="signal", yaxis='y2')
],
layout = go.Layout(
xaxis=dict(
title='日付',
tickformat='%Y-%m-%d'
),
yaxis = dict(title='株価', side='left', showgrid=False, range=[df.Low.min(), df.High.max()]),
yaxis2 = dict(title='指標', side='right', overlaying='y',
range=[min(df.Signal.min(), df.MACD.min()),
max(df.MACD.max(), df.Signal.max())]
)
)
)
fig.show()
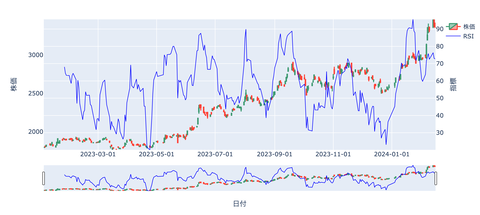
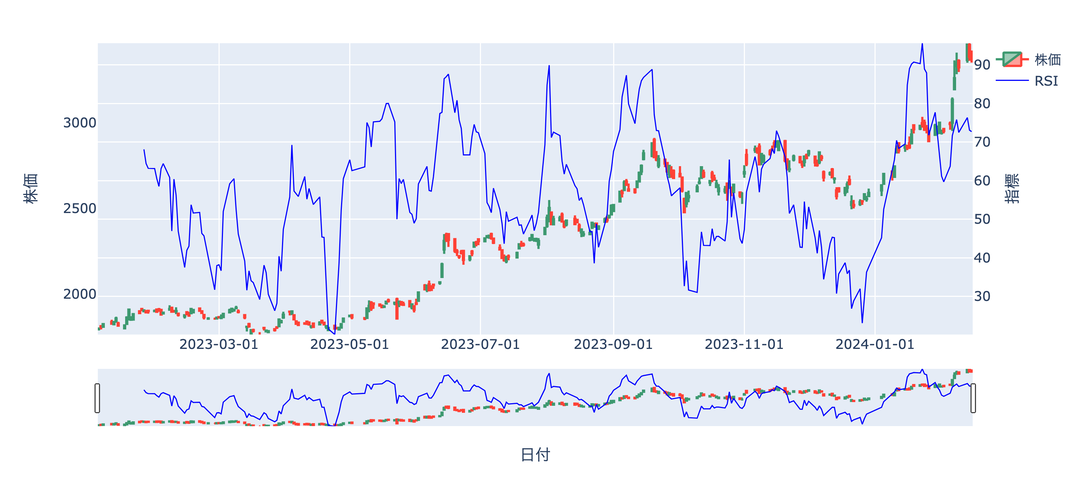
RSI
「Relative Strength Index」の略で
「Relative Strength Index」の略で
日本語に訳すと「相対力指数」
買われすぎか、売られすぎかを判断するための指標です。
過去一定期間の上げ幅(前日比)の合計を
同じ期間の上げ幅の合計と下げ幅の合計を足した数字で割って
100を掛けたもの
一般的に70~80%以上で買われすぎ
20~30%以下で売られすぎと判断します。
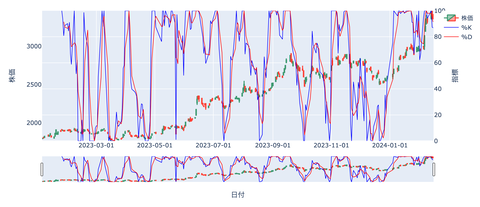
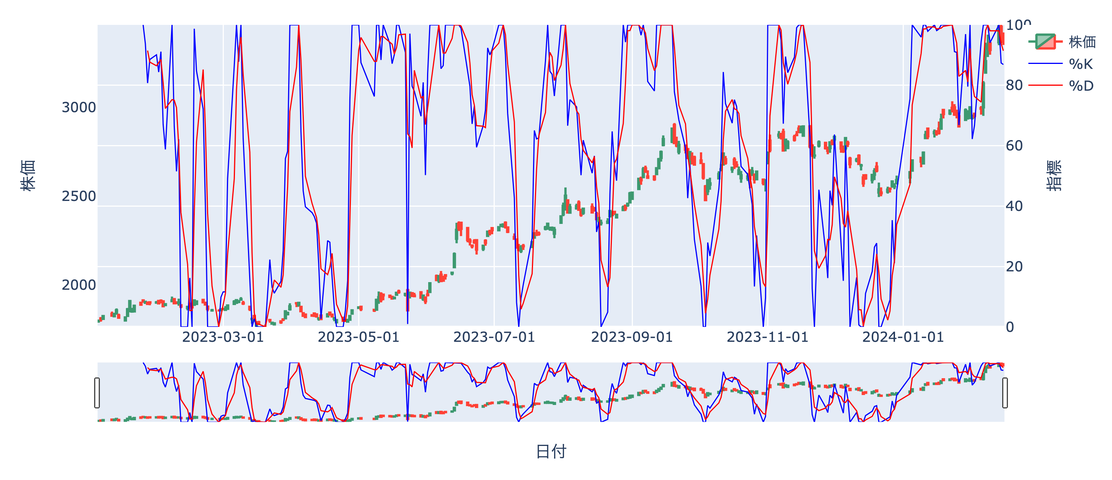
ストキャスティクス
トレードシミュレーション
ここからは株価と指標を用いて
売買のシミュレーションを行ってみましょう。
MACDでエントリーポイントを決めて売買する
簡単なシミュレーションを行ってみます。
結果を描画してみると
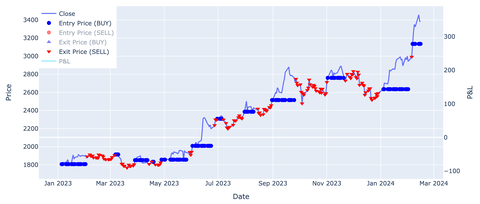
こんな感じで、売買ポイントの可視化が出来ました。
今回は簡易なデータ取得と
分析手法になっているので
気軽に始められるかと思います。
色々試してみて下さいね
それでは。
# RSI
fig = go.Figure(
data=[
go.Candlestick(
x=df.index,
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'],
name='株価',
yaxis='y1'
),
go.Scatter(x=df.index, y=df['RSI'], line=dict(color='blue', width=1), name="RSI", yaxis='y2'),
],
layout = go.Layout(
xaxis=dict(
title='日付',
tickformat='%Y-%m-%d'
),
yaxis = dict(title='株価', side='left', showgrid=False, range=[df.Low.min(), df.High.max()]),
yaxis2 = dict(title='指標', side='right', overlaying='y',
range=[df.RSI.min(), df.RSI.max()]
)
)
)
fig.show()
ストキャスティクス
チャートは%K(Fast)と%D(Slow)の2本の線で表され
数値は0%から100%の範囲で推移します。
%Kラインは相場に対して敏感に動き
Dラインは%Kラインよりも遅く動きますが
より重要とされているのは%Dラインです。
一般的には20~30%以下で売られすぎ
70~80%以上で買われすぎと判断しますが
相場の勢いが強い場合には
20%や80%を突破することもあります。
20%や80%を突破することもあります。
# ストキャスティクス
fig = go.Figure(
data=[
go.Candlestick(
x=df.index,
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'],
name='株価',
yaxis='y1'
),
go.Scatter(x=df.index, y=df['%K'], line=dict(color='blue', width=1), name="%K", yaxis='y2'),
go.Scatter(x=df.index, y=df['%D'], line=dict(color='red', width=1), name="%D", yaxis='y2')
],
layout = go.Layout(
xaxis=dict(
title='日付',
tickformat='%Y-%m-%d'
),
yaxis = dict(title='株価', side='left', showgrid=False, range=[df.Low.min(), df.High.max()]),
yaxis2 = dict(title='指標', side='right', overlaying='y',
range=[min(df['%K'].min(), df['%D'].min()),
max(df['%K'].max(), df['%D'].max())]
)
)
)
fig.show()
トレードシミュレーション
ここからは株価と指標を用いて
売買のシミュレーションを行ってみましょう。
MACDでエントリーポイントを決めて売買する
簡単なシミュレーションを行ってみます。
# トレードのシミュレーションを行う関数
def simulate_trades(df):
positions = [] # トレードのポジション(買い or 売り)
entry_prices = [] # エントリー価格
exit_prices = [] # エグジット価格
pnl = [] # 損益
for i in range(len(df)):
if i == 0:
positions.append(None)
entry_prices.append(None)
exit_prices.append(None)
pnl.append(None)
else:
if df['MACD'][i] > df['Signal'][i] and df['MACD'][i-1] <= df['Signal'][i-1]:
# MACDがシグナルを上回った時に買いポジション
positions.append('Buy')
entry_prices.append(df['Close'][i])
exit_prices.append(None)
pnl.append(None)
elif df['MACD'][i] < df['Signal'][i] and df['MACD'][i-1] >= df['Signal'][i-1]:
# MACDがシグナルを下回った時に売りポジション
positions.append('Sell')
entry_prices.append(df['Close'][i])
exit_prices.append(None)
pnl.append(None)
elif positions[-1] == 'Buy':
# 買いポジションを保持している場合
positions.append('Buy')
entry_prices.append(entry_prices[-1])
exit_prices.append(df['Close'][i])
pnl.append(df['Close'][i] - entry_prices[-1])
elif positions[-1] == 'Sell':
# 売りポジションを保持している場合
positions.append('Sell')
entry_prices.append(entry_prices[-1])
exit_prices.append(df['Close'][i])
pnl.append(entry_prices[-1] - df['Close'][i])
else:
positions.append(None)
entry_prices.append(None)
exit_prices.append(None)
pnl.append(None)
df['Position'] = positions
df['Entry Price'] = entry_prices
df['Exit Price'] = exit_prices
df['P&L'] = pnl
return df
# トレードのシミュレーションを実行
df = simulate_trades(df)
結果を描画してみると
# プロット用のデータを作成
buy_indices = df[df['Position'] == 'Buy'].index
sell_indices = df[df['Position'] == 'Sell'].index
fig = go.Figure()
# Closeをプロット
fig.add_trace(go.Scatter(x=df.index, y=df['Close'], name='Close', mode='lines'))
# Entry Priceをプロット
fig.add_trace(go.Scatter(x=df.loc[buy_indices].index, y=df.loc[buy_indices]['Entry Price'],
name='Entry Price (BUY)', mode='markers', marker=dict(color='blue', size=8)))
fig.add_trace(go.Scatter(x=df.loc[sell_indices].index, y=df.loc[sell_indices]['Entry Price'],
name='Entry Price (SELL)', mode='markers', marker=dict(color='red', size=8)))
# Exit Priceをプロット
fig.add_trace(go.Scatter(x=df.loc[buy_indices].index, y=df.loc[buy_indices]['Exit Price'],
name='Exit Price (BUY)', mode='markers', marker=dict(color='blue', size=8, symbol='triangle-up')))
fig.add_trace(go.Scatter(x=df.loc[sell_indices].index, y=df.loc[sell_indices]['Exit Price'],
name='Exit Price (SELL)', mode='markers', marker=dict(color='red', size=8, symbol='triangle-down')))
# P&Lをプロット(二番目の軸)
fig.add_trace(go.Scatter(x=df.index, y=df['P&L'], name='P&L', mode='lines', yaxis='y2'))
# レイアウト設定
fig.update_layout(title='Trading Simulation',
xaxis_title='Date',
yaxis=dict(title='Price', side='left'),
yaxis2=dict(title='P&L', side='right', overlaying='y', showgrid=False),
legend=dict(x=0, y=1),
hovermode='x unified')
# グラフの表示
fig.show()
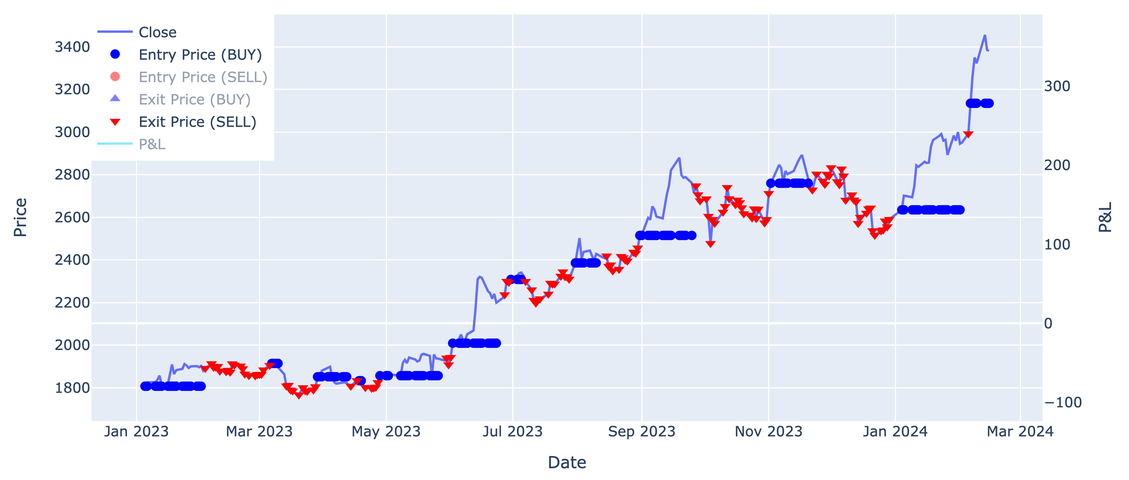
こんな感じで、売買ポイントの可視化が出来ました。
今回は簡易なデータ取得と
分析手法になっているので
気軽に始められるかと思います。
色々試してみて下さいね
それでは。