
今回はたった2行で
機械学習の精度検証が出来ちゃう
Lazypredictを試してみました
解説動画はこちら
このライブラリは
機械学習用のモデルを自動作成して
複数のモデルを比較してくれます
これがgithubです
Lazypredict
ドキュメントとしては
それほど情報量が多くないようです
コードなどもシンプルで
かなり使いやすい印象ですね
GoogleColabで動かせるので
使いたい方はコードを参考にしてみてください。
まず最初はライブラリのインストールです
GoogleColabなら追加のインストールが
無くても動くと思います。
このライブラリは
数値を予測する回帰モデルと
種別を予測する判別モデル
2種類の機械学習モデルの比較を行えます
最初は判別モデルをみてみましょう
データはscikit-learnのデータセットを使います
load_wine
説明変数
目的変数
こんな感じのデータです
読み込みのコードはこちら
これでデータが用意できたので
次は学習データの分割です
トレーニング7 , テストサイズ3で分割します
最後にlazypredictで
予測モデルの作成です
分類モデルを複数自動で生成し
その精度検証の結果と
予測結果を出してくれます
モデルの作成、検証部分は2行でいけます
分類モデルの検証はLazyClassifierを使います
最後の行の変数
models , predictions
に精度検証の結果と
予測結果が格納される仕組みです

こんな感じで予測モデルを一気に検証してくれます
テストデータの予測結果も見てみましょう
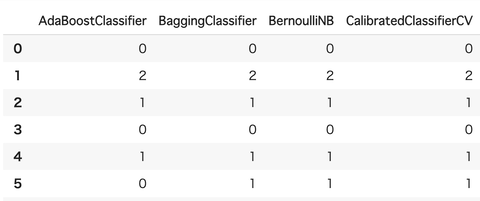
列方向は各モデルで
行がテストデータです
load_boston
ボストン住宅価格のデータです
学習データの分割も同様です
回帰の場合はLazyRegressorを使用します
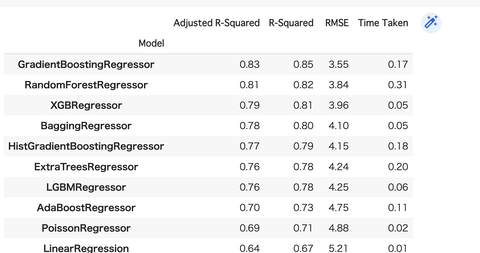
こんな感じの結果になりました
データを突っ込めばどの手法の精度が高くなるのかを
AutoMLで似たようなものに
PyCaretというのが有りますが
Lazypredictの方がバグが出なくて
良いかもしれないなーと思いました
検証をパパッとやりたい方には
かなり良いライブラリかと思いますので
試したい方はコードを参考にしていただければと思います
それでは
機械学習の精度検証が出来ちゃう
Lazypredictを試してみました
解説動画はこちら
このライブラリは
機械学習用のモデルを自動作成して
複数のモデルを比較してくれます
これがgithubです
Lazypredict
ドキュメントとしては
それほど情報量が多くないようです
コードなどもシンプルで
かなり使いやすい印象ですね
GoogleColabで動かせるので
使いたい方はコードを参考にしてみてください。
まず最初はライブラリのインストールです
# ライブラリのインストール pip install lazypredict30秒くらいでインストールも終わります。
GoogleColabなら追加のインストールが
無くても動くと思います。
このライブラリは
数値を予測する回帰モデルと
種別を予測する判別モデル
2種類の機械学習モデルの比較を行えます
最初は判別モデルをみてみましょう
データはscikit-learnのデータセットを使います
load_wine
ワインの品種に関するデータセットで
14列178個のデータがあり
3クラス分類で予測します
3クラス分類で予測します
説明変数
alcohol アルコール濃度
malic_acid リンゴ酸
ash 灰
alcalinity_of_ash 灰のアルカリ成分
magnesium マグネシウム
total_phenols 総フェノール類量
flavanoids フラボノイド(ポリフェノールらしい)
nonflavanoid_phenols 非フラボノイドフェノール類
proanthocyanins プロアントシアニジン(ポリフェノールの一種らしい)
color_intensity 色の強さ
hue 色合い
od280/od315_of_diluted_wines ワインの希釈度合い
proline プロリン(アミノ酸の一種らしい)
目的変数
ワインの品種
こんな感じのデータです
読み込みのコードはこちら
from sklearn import datasets
import pandas as pd
df = datasets.load_wine(as_frame=True).frame
print('行列数 : ' , df.shape)
print('ターゲットの種別数 : ' , df['target'].nunique())
df.head()
これでデータが用意できたので
次は学習データの分割です
トレーニング7 , テストサイズ3で分割します
# 学習データの分割 from sklearn.model_selection import train_test_split X = df.iloc[0: , 0:-1] Y = df['target'] # トレーニング7 , テストサイズ3で分割 x_train, x_test, y_train, y_test = train_test_split(X , Y , test_size=0.3 , random_state=0) x_train.shape, x_test.shape, y_train.shape, y_test.shape((124, 13), (54, 13), (124,), (54,))
最後にlazypredictで
予測モデルの作成です
分類モデルを複数自動で生成し
その精度検証の結果と
予測結果を出してくれます
モデルの作成、検証部分は2行でいけます
分類モデルの検証はLazyClassifierを使います
# lazypredictのインポート import lazypredict # 回帰予測 #from lazypredict.Supervised import LazyRegressor # 分類問題 from lazypredict.Supervised import LazyClassifier # 予測モデルの作成(たったの2行だけ) clf = LazyClassifier(verbose=1,ignore_warnings=True,predictions=True) models , predictions = clf.fit(x_train , x_test , y_train , y_test)
最後の行の変数
models , predictions
に精度検証の結果と
予測結果が格納される仕組みです
作成した予測モデルの比較を見てみましょう
# モデルの比較 models

こんな感じで予測モデルを一気に検証してくれます
テストデータの予測結果も見てみましょう
# テストデータ で予測 predictions

列方向は各モデルで
行がテストデータです
回帰モデルも同様に試してみましょう
load_boston
ボストン住宅価格のデータです
from sklearn import datasets
import pandas as pd
data = datasets.load_boston()
boston_df = pd.DataFrame(data=data["data"] , columns=data["feature_names"])
boston_df['MEDV'] = data["target"]
print('行列数 : ' , boston_df.shape)
print('ターゲットの平均値 : ' , boston_df['MEDV'].mean())
boston_df.head()
学習データの分割も同様です
# 学習データの分割 from sklearn.model_selection import train_test_split X = boston_df.iloc[0: , 0:-1] Y = boston_df['MEDV'] # トレーニング7 , テストサイズ3で分割 x_train, x_test, y_train, y_test = train_test_split(X , Y , test_size=0.3 , random_state=0) x_train.shape, x_test.shape, y_train.shape, y_test.shape回帰モデルの検証も2行でいけますが
回帰の場合はLazyRegressorを使用します
# lazypredictのインポート import lazypredict # 回帰予測 from lazypredict.Supervised import LazyRegressor # 分類問題 #from lazypredict.Supervised import LazyClassifier # 予測モデルの作成(たったの2行だけ) reg = LazyRegressor(verbose=1,ignore_warnings=True,predictions=True) models , predictions = reg.fit(x_train , x_test , y_train , y_test) # モデルの比較 models

こんな感じの結果になりました
まとめ
データを突っ込めばどの手法の精度が高くなるのかを
結構な速さで出してくれるので
初めて予測モデルを作るデータには
最適かもしれません
初めて予測モデルを作るデータには
最適かもしれません
AutoMLで似たようなものに
PyCaretというのが有りますが
Lazypredictの方がバグが出なくて
良いかもしれないなーと思いました
検証をパパッとやりたい方には
かなり良いライブラリかと思いますので
試したい方はコードを参考にしていただければと思います
それでは

