
今回はセイバーメトリクスについて
少し調べてみました。
解説動画はこちら
さて
今回はセイバーメトリクスについてです
知らない方もいるかもしれないので
簡単な説明ですが
ざっくり考えると
勝つためにデータ分析しましょう
ってことですね。
なので、今回は
まず、データに関しては
こちらのサイトのデータを参考にしています。
プロ野球データFreak
さて、チームの成績データを見てみましょう。
TSVやCSVに取得したデータを
まとめていれば、ファイルの読み込みが出来ます。
ファイルの読み込み
今回使用するのは、こんな感じのデータです。
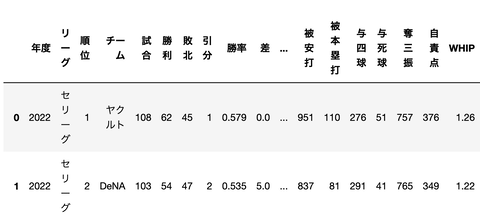
2009 - 2022年8月20日までのデータです。
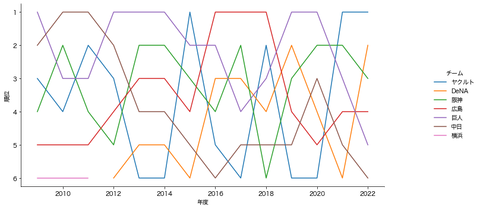
さて次は、最近のリーグ成績を見てみましょう。
こんな感じのコードで時系列での
成績をまとめることが出来ます。
順位(Y軸)は反転させておくと
いい感じになります。
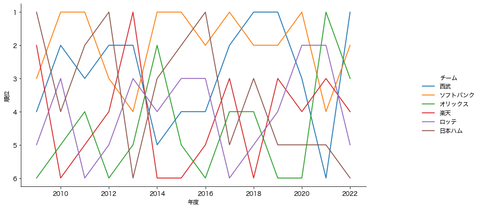
こちらはパリーグです
これで見ると、セリーグは順位変動が激しく
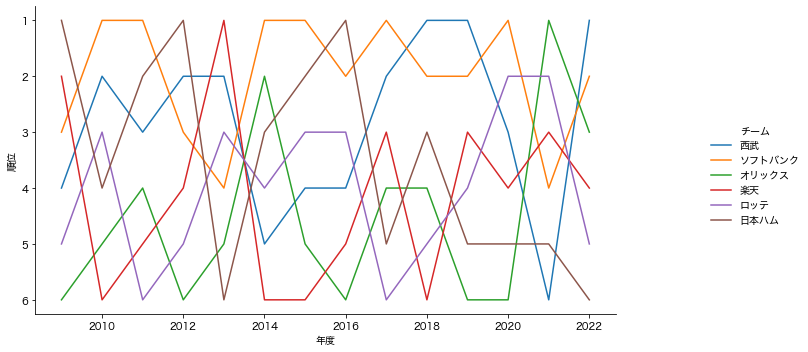
パリーグは特にソフトバンクが強いですね
ここ最近は5位以下になったことが無さそうです
次は勝率を見てみましょう。
2009 - 2022までの全試合での全チームの勝率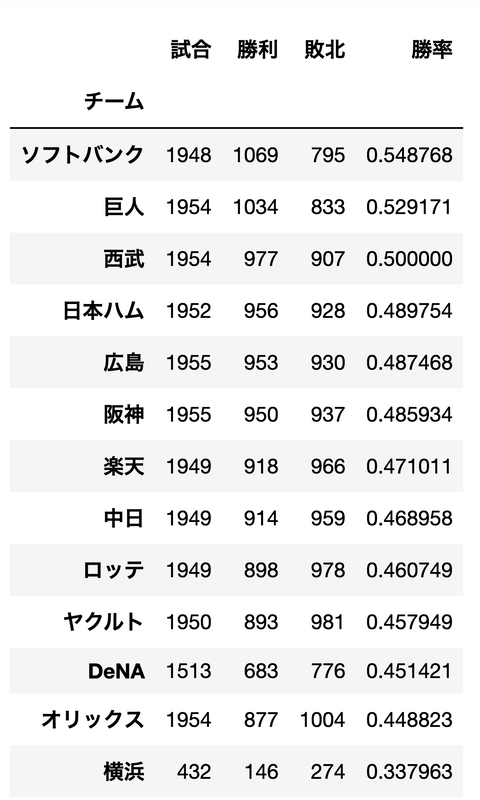
パリーグはソフトバンク
セリーグは巨人
の勝率が良いですね
とはいえ、べらぼうに差があるわけでは
無いようです。
次はこの勝利数に貢献する指標を見てみましょう。
勝利数に貢献しそうな指標は何か?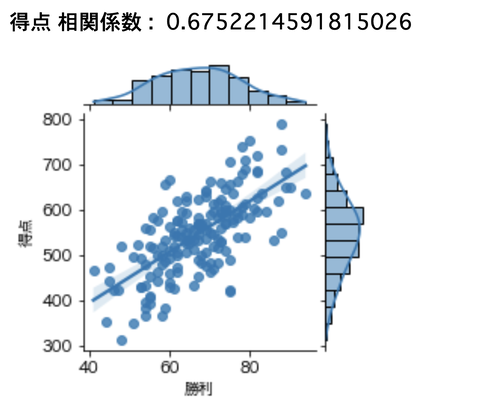
勝利数に貢献しそうな指標としては
得点が一番関係性が高そうです。
野球のルールの性質上
相手チームよりもたくさん点を取った方が勝つので
得点数は勝利に貢献するのは当たり前でしょうね。
次はこの得点に貢献する指標を見てみましょう。
得点に貢献しそうな指標は?
OPSは
得点数だと0.870
平均得点だと0.956
という高い相関係数になります。
OPSはOn-base plus sluggingの略で
次回はこの、OPS周りを
詳しく深掘りしていきたいと思います。
今回はここまでです
それでは。
少し調べてみました。
解説動画はこちら
さて
今回はセイバーメトリクスについてです
知らない方もいるかもしれないので
簡単な説明ですが
セイバーメトリクスとは
野球においてデータを
統計学的見地から客観的に分析し
統計学的見地から客観的に分析し
選手の評価や戦略を考える
分析手法のことです。
分析手法のことです。
ざっくり考えると
勝つためにデータ分析しましょう
ってことですね。
なので、今回は
勝利に貢献する指標を
見つけてみようと思います。
見つけてみようと思います。
まず、データに関しては
こちらのサイトのデータを参考にしています。
プロ野球データFreak
さて、チームの成績データを見てみましょう。
TSVやCSVに取得したデータを
まとめていれば、ファイルの読み込みが出来ます。
ファイルの読み込み
import pandas as pd
team_df = pd.read_table('baseball_all_team_stats2.tsv')
team_df.shape
(168, 51)今回使用するのは、こんな感じのデータです。

2009 - 2022年8月20日までのデータです。
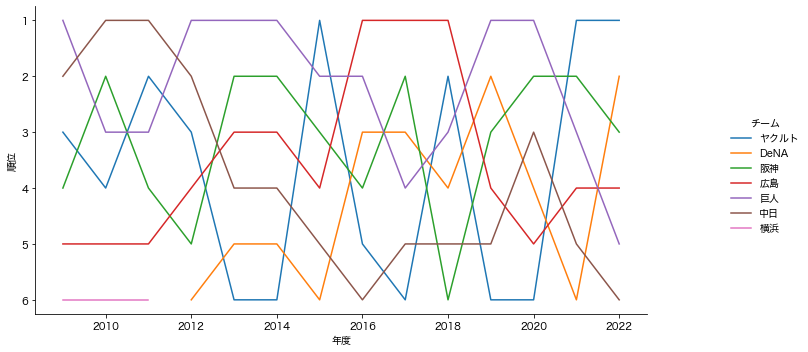
さて次は、最近のリーグ成績を見てみましょう。
こんな感じのコードで時系列での
成績をまとめることが出来ます。
順位(Y軸)は反転させておくと
いい感じになります。
import matplotlib.pyplot as plt import seaborn as sns # セリーグ se_league = team_df[team_df['リーグ']=='セリーグ'] g = sns.relplot(x='年度', y='順位', hue='チーム' , data=se_league, kind='line') g.fig.axes[0].invert_yaxis() g.fig.set_figwidth(12)
こちらはパリーグです
これで見ると、セリーグは順位変動が激しく
パリーグは特にソフトバンクが強いですね
ここ最近は5位以下になったことが無さそうです
次は勝率を見てみましょう。
2009 - 2022までの全試合での全チームの勝率
groupby = team_df[['チーム','試合','勝利','敗北']].groupby('チーム').sum()
groupby['勝率'] = groupby['勝利'] / groupby['試合']
groupby.sort_values('勝率',ascending=False)
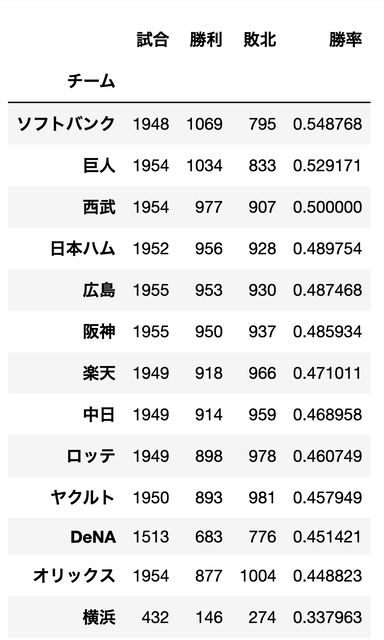
パリーグはソフトバンク
セリーグは巨人
の勝率が良いですね
とはいえ、べらぼうに差があるわけでは
無いようです。
次はこの勝利数に貢献する指標を見てみましょう。
勝利数に貢献しそうな指標は何か?
target_kpi = ['得点', '平均得点', '失点', '平均失点', '打率', '本塁打','防御率', '安打', '出塁率', '長打率', 'OPS']
for kpi in target_kpi:
tmp_df = team_df[['チーム','勝利'] + [kpi]]
print(kpi , '相関係数 : ' , tmp_df.corr().iloc[1,0])
g=sns.jointplot(x='勝利', y=kpi, data=tmp_df,kind='reg')
g.fig.set_figwidth(3)
g.fig.set_figheight(3)
plt.show()
# 相関係数のみ計算する
corrs = {}
for kpi in target_kpi:
tmp_df = team_df[['チーム','勝利'] + [kpi]]
corrs[kpi] = tmp_df.corr().iloc[1,0]
for k,v in sorted(corrs.items() , reverse=True , key=lambda x:x[1]):
print(k,v)
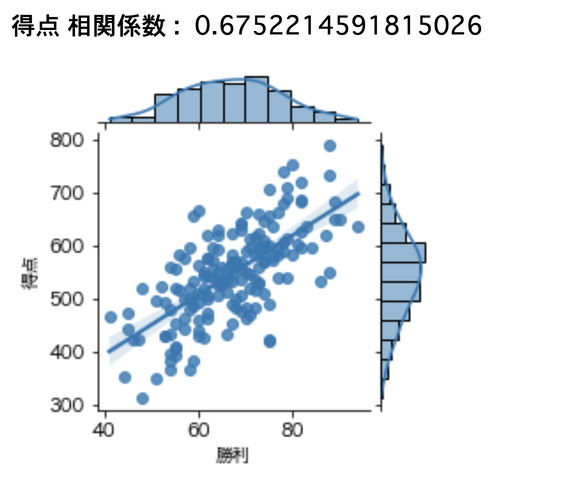
得点 0.6752214591815026
安打 0.6266412461266061
打率 0.5737515556643754
OPS 0.5707190644752489
出塁率 0.5601397549262012
平均得点 0.5484023969333554
長打率 0.5206867389057273
本塁打 0.4614069008549154
失点 -0.03810712231263921
平均失点 -0.28881452409175656
防御率 -0.30572213281469424
勝利数に貢献しそうな指標としては
得点が一番関係性が高そうです。
野球のルールの性質上
相手チームよりもたくさん点を取った方が勝つので
得点数は勝利に貢献するのは当たり前でしょうね。
次はこの得点に貢献する指標を見てみましょう。
得点に貢献しそうな指標は?
target_kpi = ['打率', '本塁打', '安打', '出塁率', '長打率', 'OPS']
corrs = {}
for kpi in target_kpi:
tmp_df = team_df[['チーム','得点'] + [kpi]]
corrs[kpi] = tmp_df.corr().iloc[1,0]
for k,v in sorted(corrs.items() , reverse=True , key=lambda x:x[1]):
print(k,v)OPS 0.8708254335866881
長打率 0.8159000896409998
安打 0.8097657028521518
出塁率 0.8054269840935689
本塁打 0.7637663066912697
打率 0.7457514146368397
平均得点だと
OPS 0.9567899908827453
長打率 0.9145865090996436
出塁率 0.8454041544924719
本塁打 0.7794856511615135
打率 0.7363115009552308
安打 0.5156269035543274
OPSは
得点数だと0.870
平均得点だと0.956
という高い相関係数になります。
OPSはOn-base plus sluggingの略で
野球において打者を評価する指標の1つで
出塁率と長打率を足し合わせた値になります。
こういった指標を一つ一つ検証し
どんな指標が貢献するのかを探るのも
セイバーメトリクスの醍醐味かと思います。
今回は勝利数に関しては得点
得点に関してはOPSが
高い貢献度があることが分かりました。
こういった指標を一つ一つ検証し
どんな指標が貢献するのかを探るのも
セイバーメトリクスの醍醐味かと思います。
今回は勝利数に関しては得点
得点に関してはOPSが
高い貢献度があることが分かりました。
次回はこの、OPS周りを
詳しく深掘りしていきたいと思います。
今回はここまでです
それでは。

