
今回は文字列の検索をする際に役立つ
正規表現についてです。
解説動画はこちら
正規表現とは
さて正規表現とは何でしょうか?
正規表現のパターンのルールは細かく
一気に覚えるのが大変です。
基本的なものだと
次のようなものがあります。
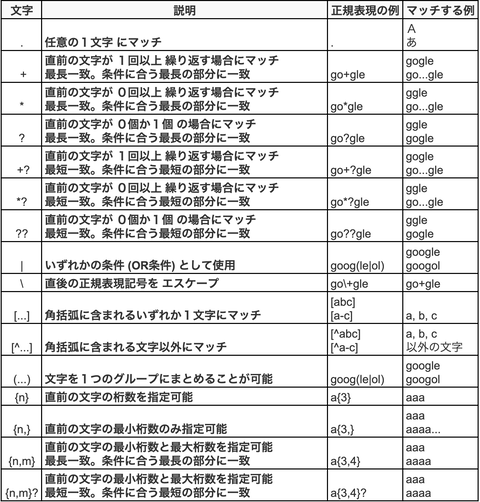
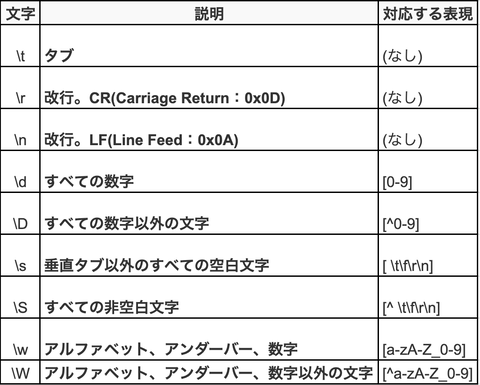
定義済みの正規表現パターンは
次のようなものがあります。
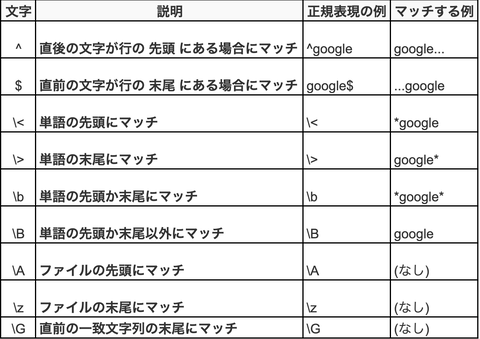
特定位置の正規表現パターンだと
次のようなものがあります。
これらを組み合わせて
色々な文字列を1つのパターンで表します。
Python言語で正規表現を使う方法
Pythonで正規表現を使うには
reライブラリを用います
ライブラリを読み込み
正規表現パターンを指定して
reライブラリの検索メソッドで
検索対象の文字列からパターンを探します。
reライブラリの検索メソッドは
結構たくさんあります。
まずはsearchメソッドです。
これは正規表現に当てはまる箇所を
位置で返します。
結果はmatchオブジェクトになるので
この中から、必要なものを取り出す形になります。
次はfindallメソッドです
これは正規表現に当てはまる部分を
リストで返します。
次はsubメソッドです
これはパターンに当てはまる部分を
他の文字列に置換することができます。
最後はsplitメソッドです
これはパターンに当てはまる部分で
文字列を分割してリスト化します。
reの検索メソッドは、目的に応じて
使い分けるのが良いでしょう。
正規表現のパターンサンプル
ここからは、正規表現の
パターンサンプルを見ていきましょう。
検索メソッドとしては「findall」を主に使用します。
a から始まって z で終わる 3 桁の文字列
a から始まって z で終わる 3 桁以上の文字列
4 桁の半角数字
4 ~ 10 桁の半角数字 (最長一致)
桁区切りのカンマ付数字
携帯電話番号
日付
日付などはちゃんと日付の妥当性も考えると
もう少し複雑なパターンを考える必要が出てきます。
ググれば、正規表現の様々なパターンを探すことができるので
自分の作りたいパターンに似たものを
流用しながら作るのが良いと思います。
覚えるのが少し大変ですが
覚える価値は有るかと思いますね。
今回はここまでです
それでは。
正規表現についてです。
解説動画はこちら
正規表現とは
さて正規表現とは何でしょうか?
正規表現は
「いくつかの文字列を一つの形式で
表現するための表現方法」です
メタ文字と呼ばれる記号を用いて
複数の文字列を1つのパターンで
表現していきます。
メタ文字には次のようなものがあります。
. ^ $ * + ? | ( ) [ ]
正規表現のパターンのルールは細かく
一気に覚えるのが大変です。
基本的なものだと
次のようなものがあります。
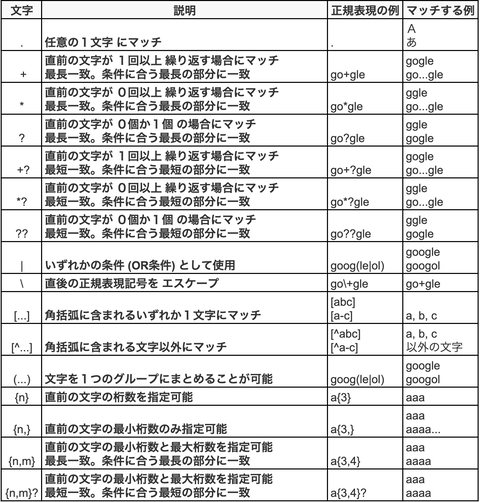
定義済みの正規表現パターンは
次のようなものがあります。
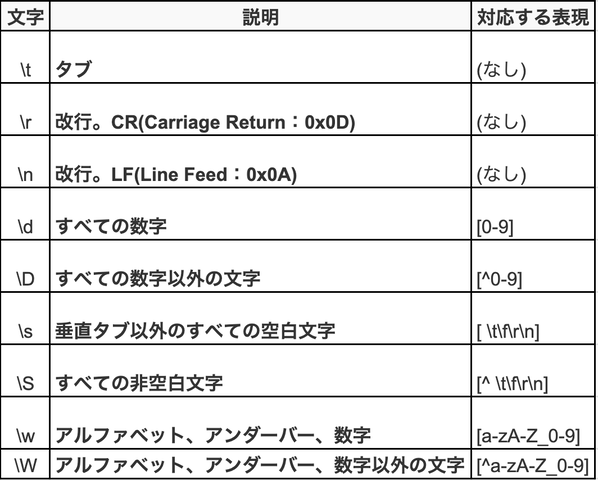
特定位置の正規表現パターンだと
次のようなものがあります。
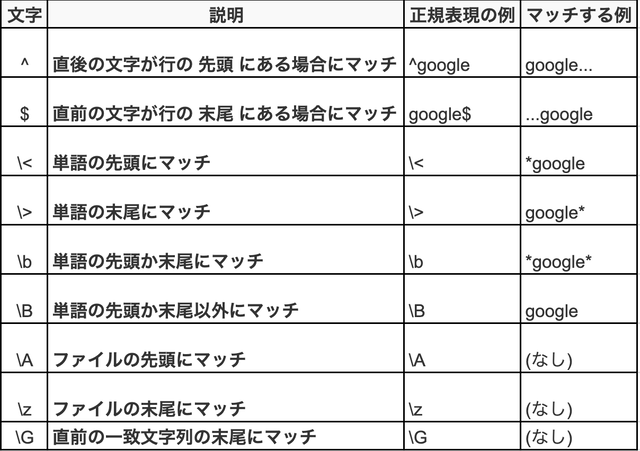
これらを組み合わせて
色々な文字列を1つのパターンで表します。
Python言語で正規表現を使う方法
Pythonで正規表現を使うには
reライブラリを用います
ライブラリを読み込み
正規表現パターンを指定して
reライブラリの検索メソッドで
検索対象の文字列からパターンを探します。
import re pattern = "正規表現パターン" text = "検索対象の文字列" re.検索メソッド(pattern , text)
reライブラリの検索メソッドは
結構たくさんあります。
まずはsearchメソッドです。
これは正規表現に当てはまる箇所を
位置で返します。
結果はmatchオブジェクトになるので
この中から、必要なものを取り出す形になります。
import re
pattern = "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+"
text = '私のメールアドレスはotupy@otupy.comです'
# 正規表現に当てはまる箇所を位置で返す
result = re.search(pattern , text)
print(result)
print(result.span())
print(result.group())
print(re.search(pattern , text).group())
<re.Match object; span=(10, 25), match='otupy@otupy.com'>
(10, 25)
otupy@otupy.com
otupy@otupy.com
次はfindallメソッドです
これは正規表現に当てはまる部分を
リストで返します。
import re pattern = "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+" text = '私のメールアドレスはotupy@otupy.comです' # 正規表現に当てはまる部分をリストで返す results = re.findall(pattern , text) print(results)['otupy@otupy.com']
次はsubメソッドです
これはパターンに当てはまる部分を
他の文字列に置換することができます。
import re pattern = "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+" text = '私のメールアドレスはotupy@otupy.comです' # 正規表現で文字列を置換する result = re.sub(pattern , 'mail_address', text) print(result)私のメールアドレスはmail_addressです
最後はsplitメソッドです
これはパターンに当てはまる部分で
文字列を分割してリスト化します。
import re pattern = "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+" text = '私のメールアドレスはotupy@otupy.comです' # 正規表現に当てはまる部分で分割する results = re.split(pattern , text) print(results)['私のメールアドレスは', 'です']
reの検索メソッドは、目的に応じて
使い分けるのが良いでしょう。
正規表現のパターンサンプル
ここからは、正規表現の
パターンサンプルを見ていきましょう。
検索メソッドとしては「findall」を主に使用します。
a から始まって z で終わる 3 桁の文字列
pattern = "a.z" text = 'abz,abc,cbz' results = re.findall(pattern , text) print(results)['abz']
a から始まって z で終わる 3 桁以上の文字列
pattern = "a.+z" text = 'abz,abc,cbz' results = re.findall(pattern , text) print(results)['abz,abc,cbz']
4 桁の半角数字
pattern = "\d{4}"
text = '123 , 1234 , 23456'
results = re.findall(pattern , text)
print(results)
['1234', '2345']4 ~ 10 桁の半角数字 (最長一致)
pattern = "\d{4,10}"
text = '123 , 1234 , 23456 , 334455667788'
results = re.findall(pattern , text)
print(results)
['1234', '23456', '3344556677']
桁区切りのカンマ付数字
pattern = "(?:^| )(\d{1,3}((?:,\d{3})*))(?=$| )"
text = '123,456 , 334455667788 1,234'
results = re.findall(pattern , text)
print(results)
[('123,456', ',456'), ('1,234', ',234')]
携帯電話番号
pattern = '[\(]{0,1}[0-9]{2,4}[\)\-\(]{0,1}[0-9]{2,4}[\)\-]{0,1}[0-9]{3,4}'
text = '携帯番号は 090-1234-5678 です 他は090-9876-4321'
results = re.findall(pattern , text)
print(results)
['090-1234-5678', '090-9876-4321']
日付
pattern = "[0-9]{4}\/[0-9]{1,2}\/[0-9]{1,2}"
text = '今日は2022/10/1です 2023/01/31'
results = re.findall(pattern , text)
print(results)
['2022/10/1', '2023/01/31']pattern = r"[0-9]{4}年[0-9]{2}月[0-9]{2}日"
text = '今日は2022年01月10日です'
results = re.findall(pattern , text)
print(results)
['2022年01月10日']日付などはちゃんと日付の妥当性も考えると
もう少し複雑なパターンを考える必要が出てきます。
まとめ
正規表現はどんなプログラム言語でも
共通的に使える表現なので覚えておくと便利です。
正規表現を作り込めば
正規表現を作り込めば
複雑なコードを書かなくても
正規表現で妥当性のチェックを行うことができ
短いコードで良くなります。
正規表現で妥当性のチェックを行うことができ
短いコードで良くなります。
ググれば、正規表現の様々なパターンを
自分の作りたいパターンに似たものを
流用しながら作るのが良いと思います。
覚えるのが少し大変ですが
覚える価値は有るかと思いますね。
今回はここまでです
それでは。

