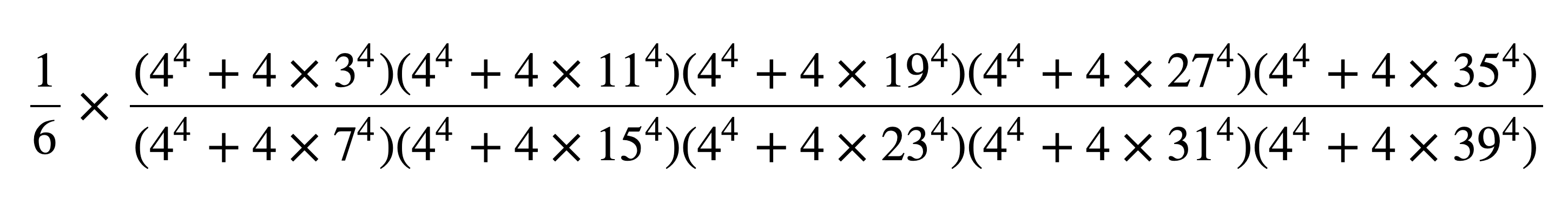たまには真面目に
数学の問題を解いてみましょう
2023年度の東大の数学の問題です
解説動画はこちら
今回は数学の問題です
手で解いたら解法が分からず
すごく時間が掛かってしまう問題も
プログラミングの力を使えば
近似解を簡単に求める事ができます
という訳で
東大の数学の問題を解いてみましょう
問題:
12個の順列の問題ですね
プログラミングの力を使えば
こういうのもシミュレーション出来ます
考え方
まずは石を用意しましょう
次にその石の並びで隣同士なのかどうかを
チェックする方法を考えてみましょう
次のようなやり方で
石のデータと判定方法を
考える事ができます
データは文字列やリスト型で定義しておくと
後で計算しやすいです
これを元にして
計算を行ってみましょう
順列を生成してチェックする方法
今回は12個の中から12個を取り出してつくる
順列になるので、その総個数は
順列は itertools ライブラリの
permutations で作る事ができます
チェック機構では判定式を返し
Trueを1、Falseを0として
条件にあった個数を返していきます
最終的に条件にあった個数と
元の順列の個数を組み合わせれば
確率が求められます
シミュレーションしてみる
総当たりの方法が思いつかなくても
シミュレーションで近似解を求める事ができます
先ほどは順列を作って繰り返しを行っていましたが
単純に回数を指定して、ランダムに並び替えた後に
チェックを行えば、順列の際の近似が求められます
チェック関数は先ほどのを用いるとして
次のような計算でシミュレーションできます
小数点第3位くらいまでは
同じ数字になりますね
近似解だと点数は貰えないかもしれませんが
点数関係ない、仕事上の計算であれば
こういったシミュレーションが行えるのが
プログラミングの役に立つポイントです
確率が分からなくても
それっぽい確率を算出する事ができるので
いろいろ便利ですねえ
色々なシミュレーションを行えるので
仕事がめちゃくちゃ捗ります
プログラミング出来ない方は
是非、この機会に覚えてみて下さい
今回は数学の問題を解く
プログラミングでのシミュレーションでした
それでは
数学の問題を解いてみましょう
2023年度の東大の数学の問題です
解説動画はこちら
今回は数学の問題です
手で解いたら解法が分からず
すごく時間が掛かってしまう問題も
プログラミングの力を使えば
近似解を簡単に求める事ができます
という訳で
東大の数学の問題を解いてみましょう
2023年度東大数学文系第3問
問題:
黒玉3個、赤玉4個、白玉5個が入っている袋から
玉を1個ずつ取り出し、取り出した玉を順に1列に12個並べる
ただし、袋から個々の玉が取り出される確率は等しいものとする
(1) どの赤玉も隣り合わない確率 p を求めよ
(2) どの赤玉も隣り合わないとき
どの黒玉も隣り合わない条件付確率 q を求めよ
どの黒玉も隣り合わない条件付確率 q を求めよ
12個の順列の問題ですね
プログラミングの力を使えば
こういうのもシミュレーション出来ます
考え方
まずは石を用意しましょう
次にその石の並びで隣同士なのかどうかを
チェックする方法を考えてみましょう
次のようなやり方で
石のデータと判定方法を
考える事ができます
# 12個の玉を作って試してみる
import numpy as np
data = ["b"]*3 + ["r"]*4 + ["w"]*5
np.random.shuffle(data)
# リストを結合して文字列にする
st = "".join(data)
# 赤玉が隣り合わないかどうか
res1 = "rr" not in st
# 上記のに加えて黒玉が隣り合わないかどうか
res2 = res1 & ("bb" not in st)
print(st)
print(res1)
print(res2)rwrwwbbrbwwr
True
False
データは文字列やリスト型で定義しておくと
後で計算しやすいです
これを元にして
計算を行ってみましょう
順列を生成してチェックする方法
今回は12個の中から12個を取り出してつくる
順列になるので、その総個数は
import math math.factorial(12)479001600
順列は itertools ライブラリの
permutations で作る事ができます
チェック機構では判定式を返し
Trueを1、Falseを0として
条件にあった個数を返していきます
最終的に条件にあった個数と
元の順列の個数を組み合わせれば
確率が求められます
import itertools
def num_check(data):
st = "".join(data)
res1 = "rr" not in st
res2 = res1 & ("bb" not in st)
return res1, res2
data = ["b"]*3 + ["r"]*4 + ["w"]*5
ans1, ans2 = 0, 0
for t in itertools.permutations(data):
t1,t2 = num_check(t)
ans1+=t1
ans2+=t2
# 総当たりの個数(順列の個数)
permutations_num = math.factorial(12)
print("1の答え : {0}".format(ans1/permutations_num))
print("2の答え : {0}".format(ans2/ans1))1の答え : 0.2545454545454545
2の答え : 0.6130952380952381
シミュレーションしてみる
総当たりの方法が思いつかなくても
シミュレーションで近似解を求める事ができます
先ほどは順列を作って繰り返しを行っていましたが
単純に回数を指定して、ランダムに並び替えた後に
チェックを行えば、順列の際の近似が求められます
チェック関数は先ほどのを用いるとして
次のような計算でシミュレーションできます
import numpy as np
N = 100000000
ans2_1, ans2_2 = 0, 0
for i in range(N):
data = ["b"]*3 + ["r"]*4 + ["w"]*5
np.random.shuffle(data)
t1,t2 = num_check(data)
ans2_1+=t1
ans2_2+=t2
print("1の答え : {0}".format(ans2_1/N))
print("2の答え : {0}".format(ans2_2/ans2_1))1の答え : 0.25452006
2の答え : 0.613167347202417
小数点第3位くらいまでは
同じ数字になりますね
近似解だと点数は貰えないかもしれませんが
点数関係ない、仕事上の計算であれば
こういったシミュレーションが行えるのが
プログラミングの役に立つポイントです
確率が分からなくても
それっぽい確率を算出する事ができるので
いろいろ便利ですねえ
色々なシミュレーションを行えるので
仕事がめちゃくちゃ捗ります
プログラミング出来ない方は
是非、この機会に覚えてみて下さい
今回は数学の問題を解く
プログラミングでのシミュレーションでした
それでは