前回作った関数を進化させてみました。
解説動画はこちら
前回はこちら
動くおっぱい関数
さて
Python言語ではmatplotlibというライブラリで
作図、可視化を行うことができます。
ということなので
曲線を描くことなどが出来てしまうわけです。
前回は黒い曲線で可視化しましたが
それだと味気ないので
色を塗ってみました。
ただし、これは静止画ではありません。
動くんです!!!
なので毎回色ぬりする範囲を
計算しないといけません。
うまく塗る範囲を考えてみました。
出来上がった関数はこちら
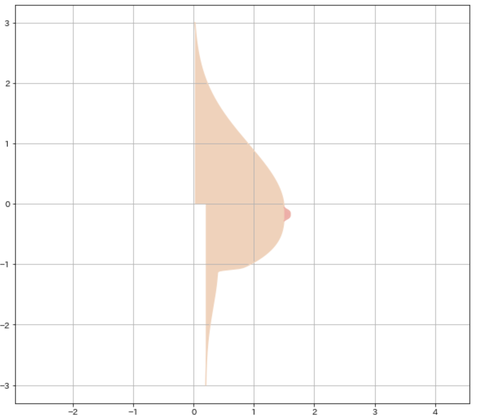
いやー素晴らしい曲線ですよね。
x,y座標に描く曲線
これは前回と一緒です。
色ぬりの指定は
書いて指定します。
デフォルトは黒いようなので
肌色を指定しています。
webで検索すれば好みの色に該当する
数値がわかるはずです。
次のポイントは
色ぬりの範囲指定です。
これで色ぬりができるんですが
範囲はxの最小値からxの最大値のようですね。
まず全体を肌色で塗り込みます。
後はB地区の計算です。
B地区の範囲を計算している部分は
def oppaiのx_5を計算している部分です。
これが曲線全体における
一番の盛り上がりの部分を
計算しているところです。
このdef oppaiではyの値を元に
x座標を計算して出力していますので
盛り上がり部分の数値がわかれば
塗る範囲も決まります。
この数値を計算すると盛り上がり部分が
ある一定の数以上の値になる部分でした。
ここを
x,yそれぞれをインデックスで取り
その部分だけピンク色を指定して
塗っています。
ようやく完成です。
tの値を変えると
プルンプルン動きます。
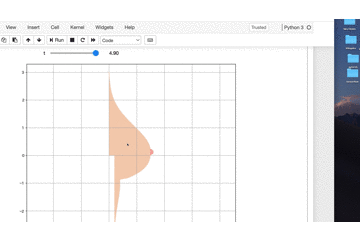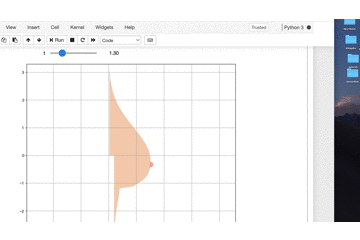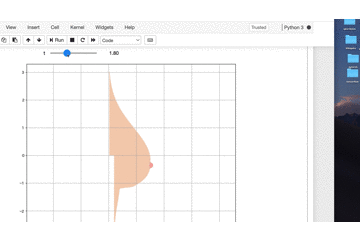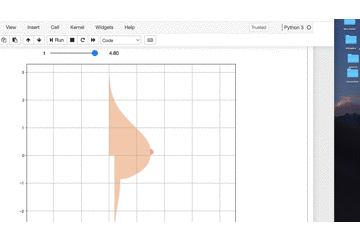
いやー今年一番の感動です。
暇でよかった!!!!
matplotlibであれば
あなたの夢も可視化できるかもしれませんね
今回はこれまでです
それでは。
解説動画はこちら
前回はこちら
動くおっぱい関数
さて
Python言語ではmatplotlibというライブラリで
作図、可視化を行うことができます。
ということなので
曲線を描くことなどが出来てしまうわけです。
前回は黒い曲線で可視化しましたが
それだと味気ないので
色を塗ってみました。
ただし、これは静止画ではありません。
動くんです!!!
なので毎回色ぬりする範囲を
計算しないといけません。
うまく塗る範囲を考えてみました。
出来上がった関数はこちら
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from ipywidgets import interact, FloatSlider, IntSlider
import warnings
warnings.simplefilter('ignore')
%matplotlib inline
def oppai(y,t):
x_1 = (1.5 * np.exp((0.12*np.sin(t)-0.5) * (y + 0.16 *np.sin(t)) ** 2)) / (1 + np.exp(-20 * (5 * y + np.sin(t))))
x_2 = ((1.5 + 0.8 * (y + 0.2*np.sin(t)) ** 3) * (1 + np.exp(20 * (5 * y +np.sin(t)))) ** -1)
x_3 = (1+np.exp(-(100*(y+1)+16*np.sin(t))))
x_4 = (0.2 * (np.exp(-(y + 1) ** 2) + 1)) / (1 + np.exp(100 * (y + 1) + 16*np.sin(t)))
x_5 = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4))
x = x_1 + (x_2 / x_3) + x_4 + x_5
return x
t = FloatSlider(min=0.1, max=5.0, step=0.1, value=0)
y = np.arange(-3, 3.01, 0.01)
@interact(t=t)
def plot_oppai(t):
x = oppai(y,t)
plt.figure(figsize=(10,9))
plt.axes().set_aspect('equal', 'datalim')
plt.grid()
b_chiku = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4))
b_index = [i for i ,n in enumerate(b_chiku>3.08361524e-003) if n]
x_2,y_2 = x[b_index],y[b_index]
plt.axes().set_aspect('equal', 'datalim')
plt.plot(x, y, '#F5D1B7')
plt.fill_between(x, y, facecolor='#F5D1B7', alpha=1)
plt.plot(x_2, y_2, '#F8ABA6')
plt.fill_between(x_2, y_2, facecolor='#F8ABA6', alpha=1)
plt.show()
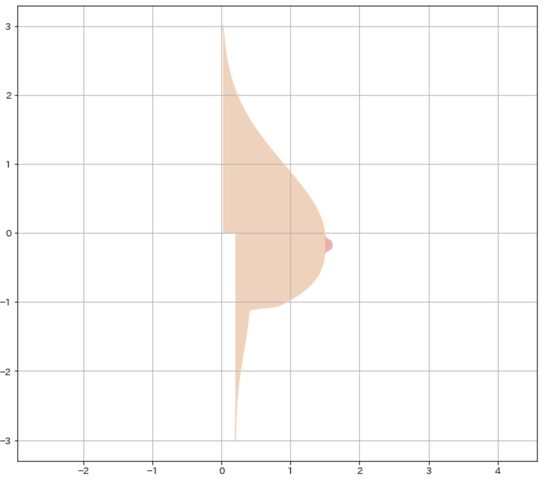
いやー素晴らしい曲線ですよね。
x,y座標に描く曲線
これは前回と一緒です。
色ぬりの指定は
#F5D1B7のように16進数のwebカラー表記で
書いて指定します。
デフォルトは黒いようなので
肌色を指定しています。
webで検索すれば好みの色に該当する
数値がわかるはずです。
次のポイントは
色ぬりの範囲指定です。
plt.fill_between
これで色ぬりができるんですが
範囲はxの最小値からxの最大値のようですね。
まず全体を肌色で塗り込みます。
後はB地区の計算です。
B地区の範囲を計算している部分は
def oppaiのx_5を計算している部分です。
これが曲線全体における
一番の盛り上がりの部分を
計算しているところです。
このdef oppaiではyの値を元に
x座標を計算して出力していますので
盛り上がり部分の数値がわかれば
塗る範囲も決まります。
この数値を計算すると盛り上がり部分が
ある一定の数以上の値になる部分でした。
ここを
x,yそれぞれをインデックスで取り
その部分だけピンク色を指定して
塗っています。
ようやく完成です。
tの値を変えると
プルンプルン動きます。
いやー今年一番の感動です。
暇でよかった!!!!
matplotlibであれば
あなたの夢も可視化できるかもしれませんね
今回はこれまでです
それでは。