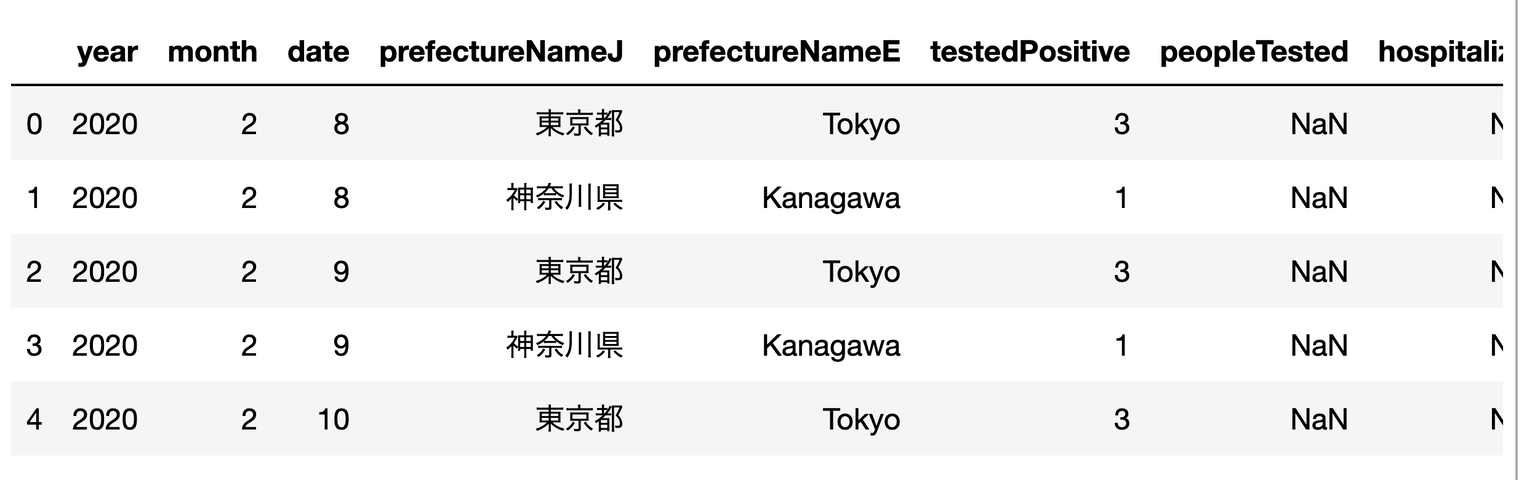
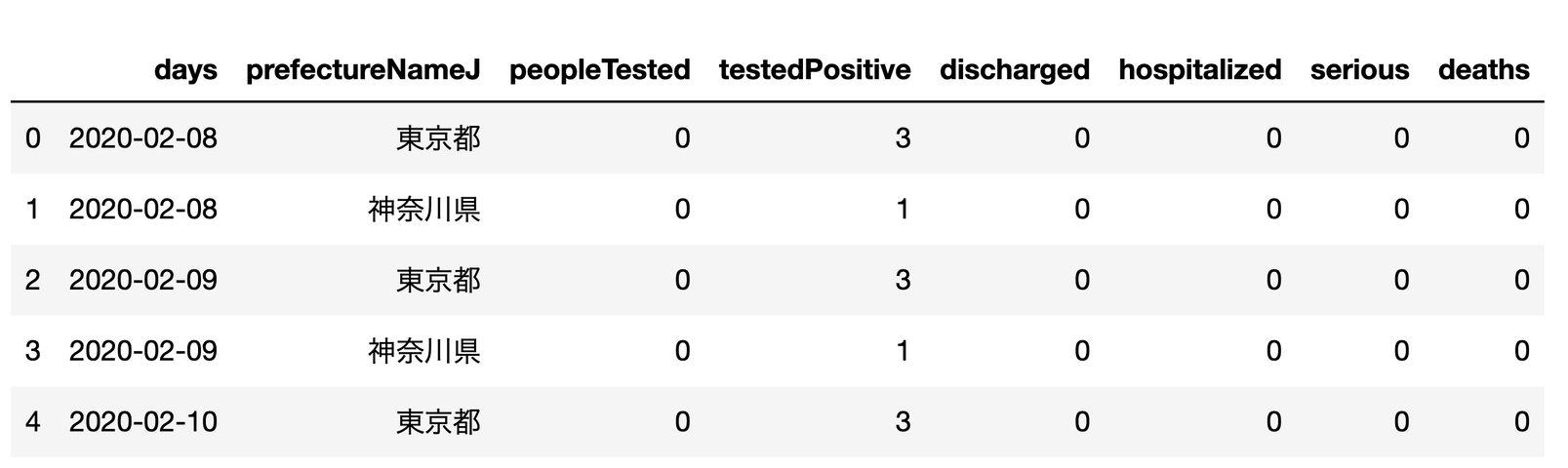
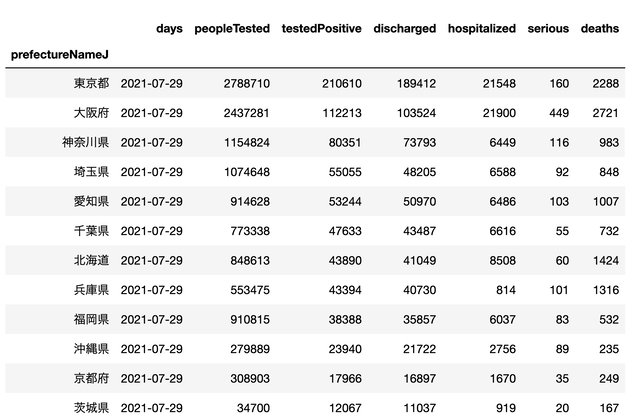
最近、やけに地震が多いので
気になって調べて
データを取って可視化してみました。
解説動画はこちら
今回のコードは
気象庁の地震データを取得して
そのデータを可視化するコードです。
先にデータが必要になるので
気になった人はコードを実行してみて下さい。
Jupyter Notebook や Google Colab で
実行できると思います。
地震データを取得する
リンクからデータを取得する
データを加工してデータフレームにする
うまく実行できたら
df という変数にデータが格納されると思います。
エラーが出る人は
ライブラリが足りなかったり
通信がうまくいっていなかったり
色々な事象が起きると思いますが
全部は対応出来ませんので
がんばって解決して下さい。
データを見てみる
データを取得できたら
データを見てみましょう。
変数 df に対して
条件を指定すれば
絞り込みをしてみる事ができます。
マグニチュード別の地震回数
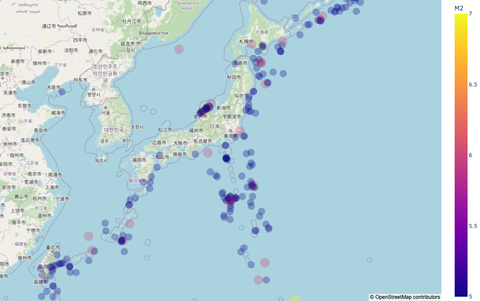
日本地図にプロットする
日本地図にプロットするには
緯度と経度が必要です。
df 変数にはカラムとして
作成しているので
地図に表示する事ができます。
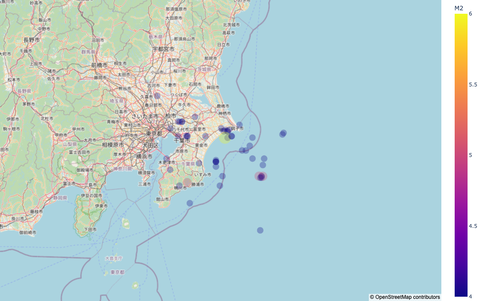
千葉県だけにすると
こんな感じです。
色々な条件で絞り込んで
地図に反映させる事ができます。
最近は地震が多いので
何かが起きている可能性がありますね。
警戒を強める意味でも
データを見る価値はあるかもしれません。
今回は地震のデータを取得して
それを可視化するコードについてでした。
それでは。
気になって調べて
データを取って可視化してみました。
解説動画はこちら
今回のコードは
気象庁の地震データを取得して
そのデータを可視化するコードです。
先にデータが必要になるので
気になった人はコードを実行してみて下さい。
Jupyter Notebook や Google Colab で
実行できると思います。
地震データを取得する
気象庁から地震の観測データを取得して
データフレームにします。
データフレームにします。
やりたい人は、30分くらいかかるので
気をつけてやって下さい。
気をつけてやって下さい。
リンクを取得
import re
import time
import pandas as pd
import requests
from tqdm import tqdm
from bs4 import BeautifulSoup
domain = "https://www.data.jma.go.jp/"
index_url = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/index.html"
res = requests.get(index_url)
soup = BeautifulSoup(res.content, "html.parser")
eq_link = [i.get("href") for i in soup.find_all("a") if len(i.get("href"))==13]
print(len(eq_link))
リンクからデータを取得する
# 地震データをテキストから取得
def data_pick(text):
row_data = []
for row in [i for i in text.split("\n") if len(i)>1][2:]:
row = row.replace("° ","°")
for i in range(7,1,-1):
row = row.replace(" "*i, " ")
row = row.replace(":"," ")
tmp = row.split(" ")
row_data.append(tmp[:-1])
return row_data
all_data = []
for day in tqdm(eq_link):
url = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/" + day
#print(url)
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
time.sleep(3.971)
text_data = soup.pre.text
all_data += data_pick(text_data)
#break
print(len(all_data))
データを加工してデータフレームにする
columns=["年","月","日","時","分","秒","緯度","経度","深さ(km)","M","震央地名"]
df = pd.DataFrame(all_data,columns=columns)
df = df[df["M"] != "-"].reset_index(drop=True)
df = df.astype({"M": float , "深さ(km)":int, "年":int,"月":int,"日":int})
df["M2"] = df["M"]//1
df["年月日"] = df.apply(lambda x : "{0}{1:02}{2:02}".format(x["年"],x["月"],x["日"]),axis=1)
def lat_lon_10(x):
tmp = x.split("°")
degree = int(tmp[0])
minute = int(tmp[1].split(".")[0])
second = int(tmp[1].split(".")[1].split("'")[0])
# 度、分、秒を10進法で表現
decimal_degree = degree + minute/60 + second/3600
return decimal_degree
df["緯度10"] = df["緯度"].map(lat_lon_10)
df["経度10"] = df["経度"].map(lat_lon_10)
df["size"] = df["M2"] ** 3
うまく実行できたら
df という変数にデータが格納されると思います。
エラーが出る人は
ライブラリが足りなかったり
通信がうまくいっていなかったり
色々な事象が起きると思いますが
全部は対応出来ませんので
がんばって解決して下さい。
データを見てみる
データを取得できたら
データを見てみましょう。
変数 df に対して
条件を指定すれば
絞り込みをしてみる事ができます。
マグニチュード別の地震回数
df[["M2","震央地名"]].groupby("M2").count().sort_index(ascending=False)
日本地図にプロットする
日本地図にプロットするには
緯度と経度が必要です。
df 変数にはカラムとして
作成しているので
地図に表示する事ができます。
import plotly.express as px
fig = px.scatter_mapbox(
data_frame=df[df["M2"]>=5],
lat="緯度10",
lon="経度10",
hover_data=["年月日","深さ(km)"],
color="M2",
size="size",
size_max=20,
opacity=0.3,
zoom=4,
height=700,
width=1500)
fig.update_layout(mapbox_style='open-street-map')
fig.update_layout(margin={"r": 0, "t": 0, "l": 0, "b": 0})
fig.show()

千葉県だけにすると
こんな感じです。

色々な条件で絞り込んで
地図に反映させる事ができます。
最近は地震が多いので
何かが起きている可能性がありますね。
警戒を強める意味でも
データを見る価値はあるかもしれません。
今回は地震のデータを取得して
それを可視化するコードについてでした。
それでは。