
今回は知らない人向けに
データベースとSQLについてを
解説してみました。
営業さんや
これから技術を学ぶ人に
むいていると思います。
解説動画はこちら
内容はめちゃくちゃ簡単な内容で
SQLについても詳細な書き方などについては
触れていません。
全く知らない、触れたことがない人向けで
30分ほどあれば読み追われると思います。
さてまず最初はデータベース編です。
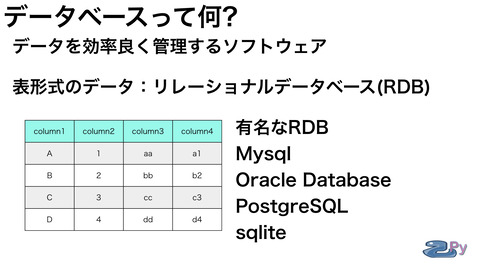
データベースとは何でしょう?
簡単に言うとデータを効率よく
管理するソフトウェアのことです。
表形式のデータを取り扱いするものは
リレーショナルデータベースと呼ばれ
RDBと略されています。
代表的なものとしては
MysqlやOracleなんかがあります。
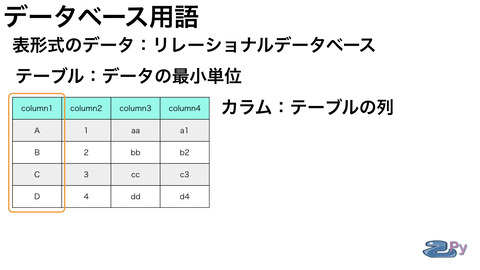
データベース界隈の用語としては
データの最小単位として
テーブルというものがあります。
テーブルは表のことで
行列のデータの集まりです。
テーブルには
カラム:列のこと

ロウ:行のこと
レコードも1件のデータで
行と同じような扱いです。
行列が交わるところはフィールドです。
スキーマはテーブルの構造を
定義したもので
テーブルのカラムには
データ型と言うものがあります。
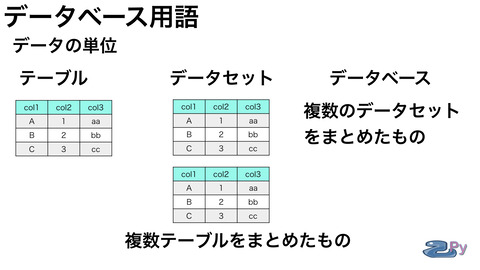
テーブルをまとめたものはデータセット
データセットをまとめて
データベースと言っていたりします。
様々なデータ型が存在します。
カラムは何かしら1つのデータ型で統一して
データが格納されています。
主なデータ型としては
文字列型
整数型
小数型
timestamp型
などがあります。

ここからはSQLの話です。
まずSQLは
リレーショナルデータベースを
操作するための言語です。
テーブルにデータを格納したり
テーブルからデータを抽出したりする際に
使用することができます。
今回は実際にSQLの実行環境などを
紹介しませんので、SQLや
文法の触りだけの紹介になります。
SQLには
DML
DDL
DCL
という3つの系統があり
それぞれにいくつかの文が存在します。

今回はその中でもよく使われる
DMLについてのみご紹介します。
一番最初はSELECT文からです。
SELECT文はデータを
抽出・参照するための文です。
たくさんの「句」で構成され
順番通りに書いて実行すると
条件に応じた結果が
出力されるというものです。

基本構成としては
7つの句があります。
1.SELECT句
2.FROM句
3.WHERE句
4.GROUP BY句
5.HAVING句
6.ORDER BY句
7.LIMIT句
上二つは何をどこから
を指定します。
下の5つは
どういう条件で抽出するか
抽出条件を書くところになります。
一番上はSELECT句です。
SELECT句は出力する物を
指定するところで
基本はカラム名を書きます。
複数ある場合は
カンマ「,」でつなぎます。
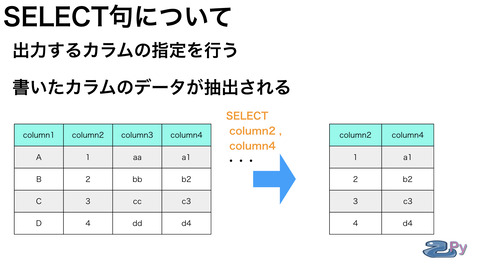
出力時はそのカラム名で
出力されますが
AS で別名をつけたりできます。

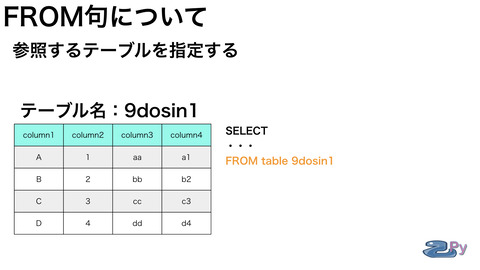
FROM句はどこのテーブルから
抽出をするか
テーブル名を書くところです。
WHERE句は条件指定をする所で
基本的にはカラムの値を条件にして
指定します。
その値に該当する結果が

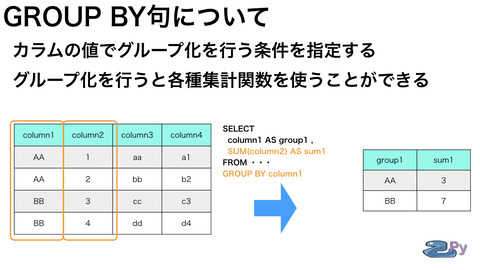
GROUP BY句は
指定したカラムの値でグループ化し
そのグループ化したもので
別のカラムの値を集計することができます。
集計には集計関数を用います。
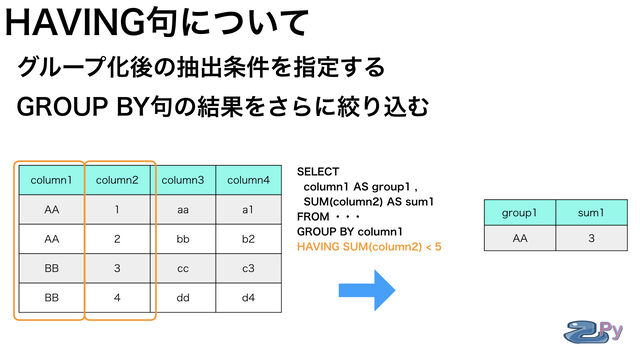
HAVING句は
GROUP BY句で指定したグループ化後の
集計結果をさらに絞り込む指定を
するところになります。

ORDER BY句は
並び替えの指定をするところです。
カラムの値で昇順か降順に
並び替えが行われます。

LIMIT句は単純に
出力行数を制御するところです。

基本構文の他にも
UNION句
JOIN句
WITH句
などが使えます。
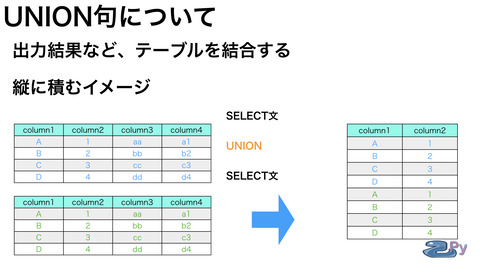
UNION句は
縦に結果をつなげるイメージです。
SELECT文同志を
UNION句でつなげたりします。
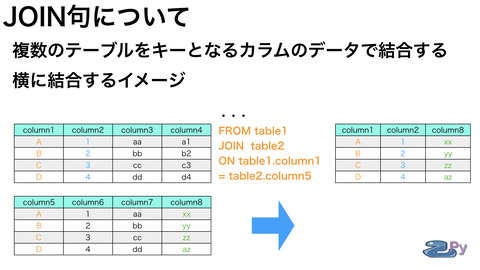
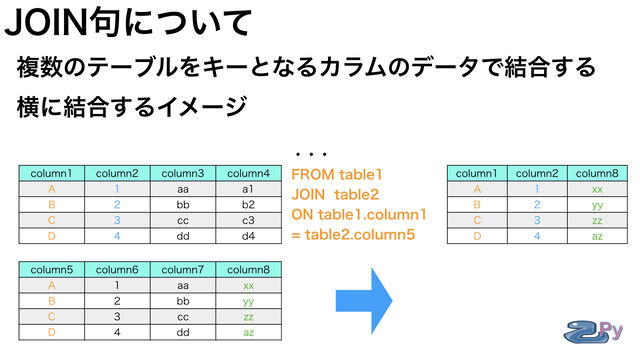
JOIN句は横につなげるイメージで
4通りの指定方法があります。
FROM句の後に
JOIN句でくっつけたいテーブルを指定し
双方にあるデータをキーにして
片方のテーブルにしかないデータを
横につなげることができます。

INNER JOINはデフォルトで
双方のテーブルにある
データが結合します。
LEFT JOINは左側に対して
右側にある物をくっつけます。
RIGHT JOINはその逆です。
FULL JOINは全てのデータを
くっつけます。
FROMの後に書いた方が左側
JOIN句に書いたものが右側になります。
WITH句は一時的なテーブルを作成でき
後続のSQLでそのテーブルを利用できます。

INSERT文はテーブルにデータを追加します。

UPDATE文はデータの更新を行い
条件指定した行のデータを書き換えます。

DELETE文はデータの削除を行い
条件指定した行の削除を行います。

以上
簡単ではありますが
データベースとSQLについて
紹介を行いました。
実際に業務で取り入れる際は
データベースをインストールしたり
実行環境を整備したり
するのが必要になります。
まずはどんなものなのか
知識を蓄えておくと
良いのかなと思います。
今回はここまでです
それでは。
データベースとSQLについてを
解説してみました。
営業さんや
これから技術を学ぶ人に
むいていると思います。
解説動画はこちら
内容はめちゃくちゃ簡単な内容で
SQLについても詳細な書き方などについては
触れていません。
全く知らない、触れたことがない人向けで
30分ほどあれば読み追われると思います。
さてまず最初はデータベース編です。

データベースとは何でしょう?
簡単に言うとデータを効率よく
管理するソフトウェアのことです。
表形式のデータを取り扱いするものは
リレーショナルデータベースと呼ばれ
RDBと略されています。
代表的なものとしては
MysqlやOracleなんかがあります。

データベース界隈の用語としては
データの最小単位として
テーブルというものがあります。
テーブルは表のことで
行列のデータの集まりです。
テーブルには
カラム:列のこと

ロウ:行のこと
レコードも1件のデータで
行と同じような扱いです。
行列が交わるところはフィールドです。
スキーマはテーブルの構造を
定義したもので
テーブルのカラムには
データ型と言うものがあります。
テーブルをまとめたものはデータセット
データセットをまとめて
データベースと言っていたりします。

様々なデータ型が存在します。
カラムは何かしら1つのデータ型で統一して
データが格納されています。
主なデータ型としては
文字列型
整数型
小数型
timestamp型
などがあります。

ここからはSQLの話です。
まずSQLは
リレーショナルデータベースを
操作するための言語です。
テーブルにデータを格納したり
テーブルからデータを抽出したりする際に
使用することができます。
今回は実際にSQLの実行環境などを
紹介しませんので、SQLや
文法の触りだけの紹介になります。
SQLには
DML
DDL
DCL
という3つの系統があり
それぞれにいくつかの文が存在します。

今回はその中でもよく使われる
DMLについてのみご紹介します。
一番最初はSELECT文からです。
SELECT文はデータを
抽出・参照するための文です。
たくさんの「句」で構成され
順番通りに書いて実行すると
条件に応じた結果が
出力されるというものです。

基本構成としては
7つの句があります。
1.SELECT句
2.FROM句
3.WHERE句
4.GROUP BY句
5.HAVING句
6.ORDER BY句
7.LIMIT句
上二つは何をどこから
を指定します。
下の5つは
どういう条件で抽出するか
抽出条件を書くところになります。
一番上はSELECT句です。
SELECT句は出力する物を
指定するところで
基本はカラム名を書きます。
複数ある場合は
カンマ「,」でつなぎます。

出力時はそのカラム名で
出力されますが
AS で別名をつけたりできます。

FROM句はどこのテーブルから
抽出をするか
テーブル名を書くところです。

WHERE句は条件指定をする所で
基本的にはカラムの値を条件にして
指定します。
その値に該当する結果が

GROUP BY句は
指定したカラムの値でグループ化し
そのグループ化したもので
別のカラムの値を集計することができます。
集計には集計関数を用います。

HAVING句は
GROUP BY句で指定したグループ化後の
集計結果をさらに絞り込む指定を
するところになります。
ORDER BY句は
並び替えの指定をするところです。
カラムの値で昇順か降順に
並び替えが行われます。

LIMIT句は単純に
出力行数を制御するところです。

基本構文の他にも
UNION句
JOIN句
WITH句
などが使えます。
UNION句は
縦に結果をつなげるイメージです。
SELECT文同志を
UNION句でつなげたりします。

JOIN句は横につなげるイメージで
4通りの指定方法があります。
FROM句の後に
JOIN句でくっつけたいテーブルを指定し
双方にあるデータをキーにして
片方のテーブルにしかないデータを
横につなげることができます。

INNER JOINはデフォルトで
双方のテーブルにある
データが結合します。
LEFT JOINは左側に対して
右側にある物をくっつけます。
RIGHT JOINはその逆です。
FULL JOINは全てのデータを
くっつけます。
FROMの後に書いた方が左側
JOIN句に書いたものが右側になります。
WITH句は一時的なテーブルを作成でき
後続のSQLでそのテーブルを利用できます。

INSERT文はテーブルにデータを追加します。

UPDATE文はデータの更新を行い
条件指定した行のデータを書き換えます。

DELETE文はデータの削除を行い
条件指定した行の削除を行います。

以上
簡単ではありますが
データベースとSQLについて
紹介を行いました。
実際に業務で取り入れる際は
データベースをインストールしたり
実行環境を整備したり
するのが必要になります。
まずはどんなものなのか
知識を蓄えておくと
良いのかなと思います。
今回はここまでです
それでは。

