
今回は音声認識ライブラリの
「Whisper」を用いて
音声の文字起こしを行ってみました
解説動画はこちら
早速使っていきましょう
Google Colabを用いて
コードを動かす事ができます
インストール
インストール方法は次の1行で簡単です
次はライブラリのインポートです
用意が出来たら
音声ファイルを置きましょう
配置場所はファイル置き場です
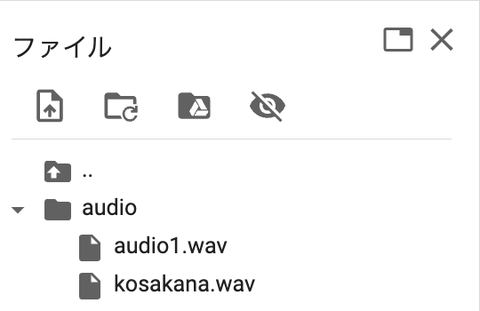
こんな感じでファイルを配置しましょう
文字起こしをするのは次のコードです
音声ファイルの中身によって
結果は変わります
いろいろ試してみて下さい
動画ではいくつかの
音声文字起こしをしているので
そちらも参考にしてみて下さい
今回はここまでです
それでは
「Whisper」を用いて
音声の文字起こしを行ってみました
解説動画はこちら
Whisperとは
OpenAIの音声認識ライブラリ
68万時間分の大規模なデータセットで
学習された自動音声認識モデル
音声から文字起こしする事ができます
早速使っていきましょう
Google Colabを用いて
コードを動かす事ができます
インストール
インストール方法は次の1行で簡単です
# whisperのインストール !pip install git+https://github.com/openai/whisper.git
次はライブラリのインポートです
# ライブラリのインポート
import whisper
model = whisper.load_model("base")
これも2行でできます用意が出来たら
音声ファイルを置きましょう
配置場所はファイル置き場です
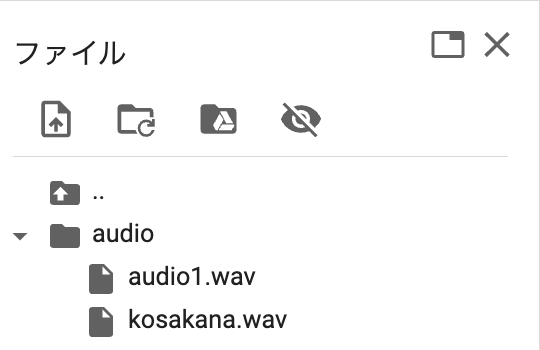
こんな感じでファイルを配置しましょう
文字起こしをするのは次のコードです
# 音声ファイルの書き起こし実行 audio_file_path = "ファイルパス" result = model.transcribe(audio_file_path) print(result["text"])
音声ファイルの中身によって
結果は変わります
いろいろ試してみて下さい
動画ではいくつかの
音声文字起こしをしているので
そちらも参考にしてみて下さい
今回はここまでです
それでは


コメントする