
たまには真面目に
仕事で使えそうなプログラミングをしてみましょう
解説動画はこちら
1.WEB上にあるCSVファイルを開く
今回はWEB上にあるファイルを
ダウンロードせず、直接開いてみましょう。
読み込みするファイルは、総務省かどっかが出している
E-statのデータです。
男女別人口-全国,都道府県(大正9年~平成27年)
これを読み込みするには
Pandasライブラリを使います。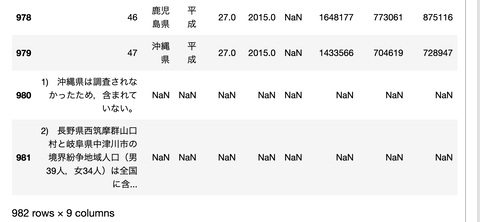
読み込みは出来ましたが
最後の方にゴミが載っています。
政府が用意しているデータは
リテラシーが低く、ゴミなので
そのままだと使えないことが多いです。
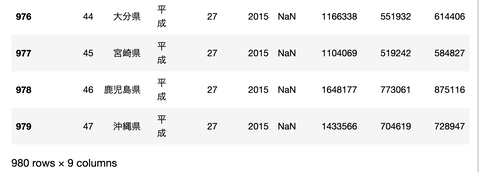
いらない部分を読み飛ばしてみましょう
skipfooter = 最後尾の行数
を加えるといらない部分を飛ばして読み込み出来ます。
Pandasライブラリを用いないで読み込みする場合は
urllibが使えます。
urllib.request.urlopenで開いたファイルは
http.client.HTTPResponseオブジェクトになります
オブジェクト.decode()で
strオブジェクトに変換できます。
リストでまとめて読み込んでしまう場合は
次のように書けばいけます。
ゴミデータが最後の3個に入ってしまっているので
リストのスライス参照で取り除くと良いでしょう。
これでpandasでは難しい1行単位での
データ操作を行えます。
2.データを見る
さて、ファイルが読み込めたので
次は中身を細かくみてみましょう。
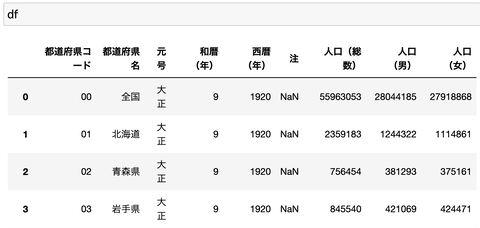
ファイルはこんな感じになっています。
全国の人口だけを見る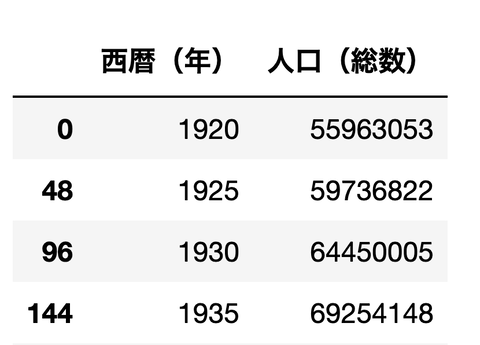
Pandasのデータフレームでは
条件抽出が行えるので
該当する部分だけを抜き出すことができます。
最近のものだけを見る(2010 , 2015)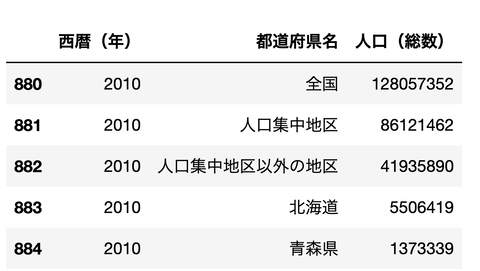
isin で値を複数指定して
条件抽出ができます。
2010 , 2015の差分を見る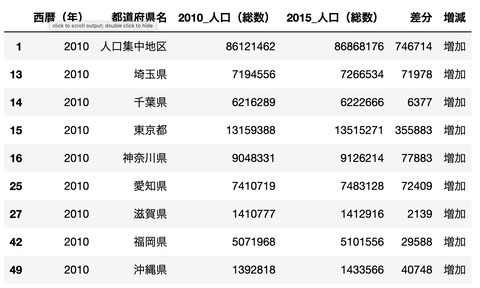
差分を見るには
まずはデータフレームとして該当するデータを
年ごとに作成しておき
それを列方向に結合させます。
のちに数値化して差分を計算することができます。
2010 - 2015で
人口が増えた都道府県は8個しか無いようですね
2020年度のデータがなかったようですが
人口は減る傾向にあります
東京都の人口推移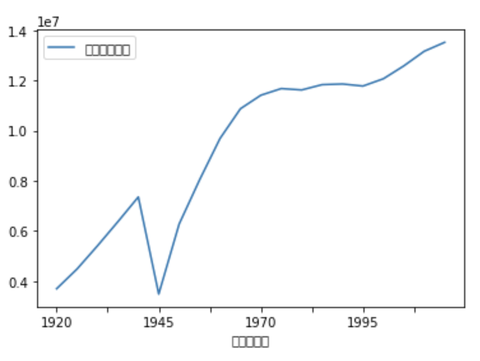
最後に東京都だけを抜き出して
人口推移を見ます
データフレームをそのまま
折れ線グラフに描画することが出来ます
東京都の人口は100年前は400万人弱
1945年に大きく減り
そこから猛烈な勢いで1970年頃までは急成長
1995年以降また増え続けています
こういうのをささっと作ることができるのが
Pythonの強みですね
Google Colabなどを使えば
Pythonをインストールしなくても
エクセルなどで開けない
ファイルが有るときは
仕事で使えそうなプログラミングをしてみましょう
解説動画はこちら
1.WEB上にあるCSVファイルを開く
今回はWEB上にあるファイルを
ダウンロードせず、直接開いてみましょう。
読み込みするファイルは、総務省かどっかが出している
E-statのデータです。
男女別人口-全国,都道府県(大正9年~平成27年)
file_url ='https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031524010&fileKind=1'
これを読み込みするには
Pandasライブラリを使います。
import pandas as pd
import warnings
warnings.simplefilter('ignore')
df = pd.read_csv(file_url , encoding='cp932')
df
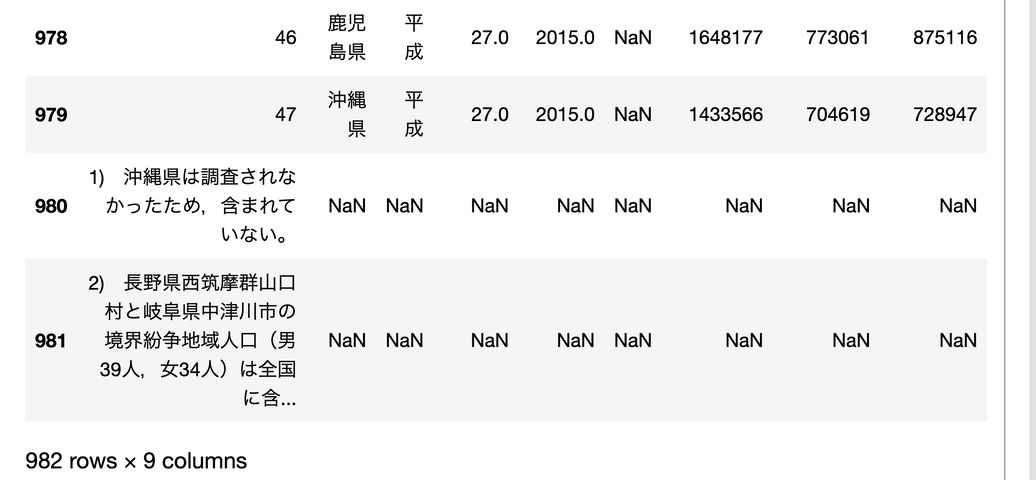
読み込みは出来ましたが
最後の方にゴミが載っています。
政府が用意しているデータは
リテラシーが低く、ゴミなので
そのままだと使えないことが多いです。
いらない部分を読み飛ばしてみましょう
skipfooter = 最後尾の行数
を加えるといらない部分を飛ばして読み込み出来ます。
df = pd.read_csv(file_url , encoding='cp932', engine="python" , skipfooter=2) df
Pandasライブラリを用いないで読み込みする場合は
urllibが使えます。
urllib.request.urlopenで開いたファイルは
http.client.HTTPResponseオブジェクトになります
オブジェクト.decode()で
strオブジェクトに変換できます。
import urllib
# そのままurlopenで開いた場合
with urllib.request.urlopen(file_url) as _f:
for row in _f:
print(row)
break
b'"\x93s\x93\xb9\x95{\x8c\xa7\x83R\x81[\x83h","\x93s\x93\xb9\x95{\x8c\xa7\x96\xbc","\x8c\xb3\x8d\x86","\x98a\x97\xef\x81i\x94N\x81j","\x90\xbc\x97\xef\x81i\x94N\x81j","\x92\x8d","\x90l\x8c\xfb\x81i\x91\x8d\x90\x94\x81j","\x90l\x8c\xfb\x81i\x92j\x81j","\x90l\x8c\xfb\x81i\x8f\x97\x81j"\r\n'# urlopenで開いてdecodeした場合
with urllib.request.urlopen(file_url) as _f:
for row in _f:
print(row.decode('cp932'))
break
"都道府県コード","都道府県名","元号","和暦(年)","西暦(年)","注","人口(総数)","人口(男)","人口(女)"
リストでまとめて読み込んでしまう場合は
次のように書けばいけます。
# urlopenで開いてlist化する
with urllib.request.urlopen(file_url) as _f:
# 改行コードで分割する
lines = _f.read().decode('cp932').split('\r\n')
lines
['"都道府県コード","都道府県名","元号","和暦(年)","西暦(年)","注","人口(総数)","人口(男)","人口(女)"',
'"00","全国","大正",9,1920,"",55963053,28044185,27918868',・・・ゴミデータが最後の3個に入ってしまっているので
リストのスライス参照で取り除くと良いでしょう。
lines[970:-3]
これでpandasでは難しい1行単位での
データ操作を行えます。
2.データを見る
さて、ファイルが読み込めたので
次は中身を細かくみてみましょう。
ファイルはこんな感じになっています。
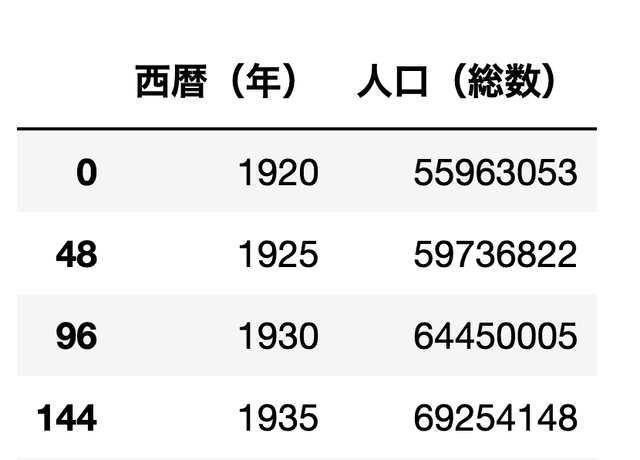
全国の人口だけを見る
df[df['都道府県名']=='全国'][['西暦(年)','人口(総数)']]
Pandasのデータフレームでは
条件抽出が行えるので
該当する部分だけを抜き出すことができます。
最近のものだけを見る(2010 , 2015)
df[df['西暦(年)'].isin([2010,2015])][['西暦(年)','都道府県名','人口(総数)']]
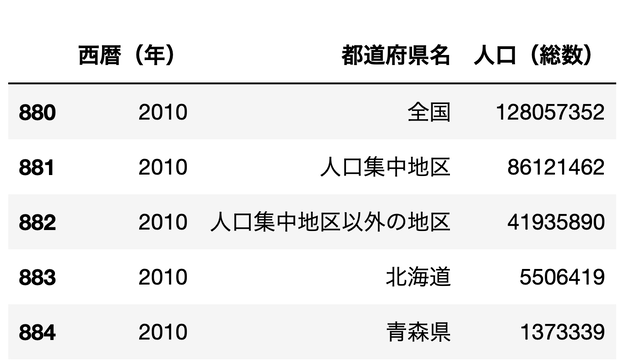
isin で値を複数指定して
条件抽出ができます。
2010 , 2015の差分を見る
# 該当年のデータを抽出 df_2010 = df[df['西暦(年)']==2010][['西暦(年)','都道府県名','人口(総数)']] df_2015 = df[df['西暦(年)']==2015][['西暦(年)','都道府県名','人口(総数)']] # インデックスのリセット df_2010.reset_index( inplace=True , drop=True) df_2015.reset_index( inplace=True , drop=True) # データフレームの結合 df_concat = pd.concat([df_2010 , df_2015[['人口(総数)']]],axis=1) df_concat.columns = ['西暦(年)', '都道府県名', '2010_人口(総数)', '2015_人口(総数)'] # 差分の計算 df_concat['差分'] = df_concat['2015_人口(総数)'].astype(int) - df_concat['2010_人口(総数)'].astype(int) df_concat['増減'] = df_concat['差分'].apply(lambda x: '減少' if x <=0 else '増加') # 人口が増加した都道府県は? df_concat[df_concat['増減']=='増加']
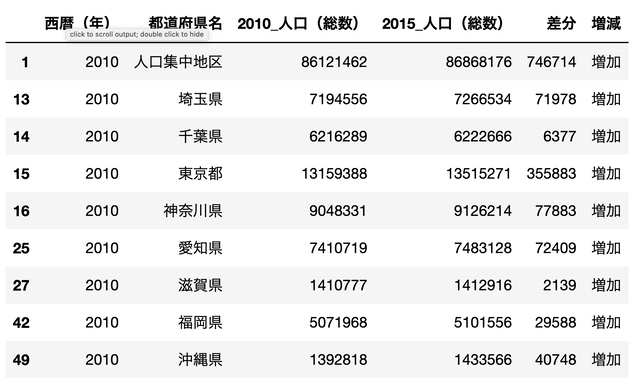
差分を見るには
まずはデータフレームとして該当するデータを
年ごとに作成しておき
それを列方向に結合させます。
のちに数値化して差分を計算することができます。
2010 - 2015で
人口が増えた都道府県は8個しか無いようですね
2020年度のデータがなかったようですが
人口は減る傾向にあります
東京都の人口推移
df_plot = df[df['都道府県名']=='東京都'][['西暦(年)','人口(総数)']] df_plot.reset_index( inplace=True , drop=True) df_plot['人口(総数)'] = df_plot['人口(総数)'].astype(int) df_plot['西暦(年)'] = df_plot['西暦(年)'].astype(str) df_plot.plot(kind='line',x='西暦(年)')
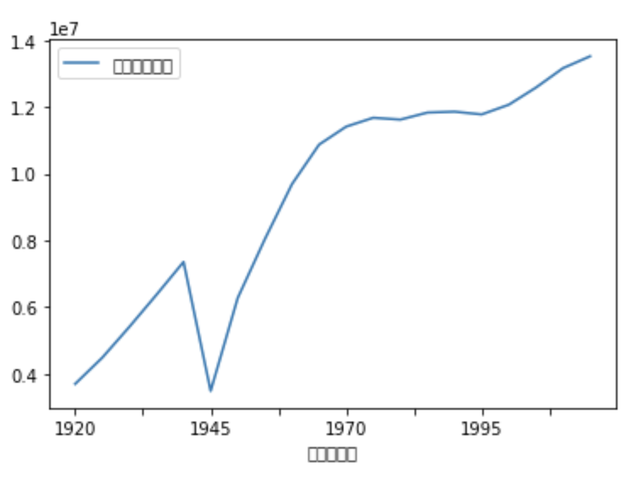
最後に東京都だけを抜き出して
人口推移を見ます
データフレームをそのまま
折れ線グラフに描画することが出来ます
東京都の人口は100年前は400万人弱
1945年に大きく減り
そこから猛烈な勢いで1970年頃までは急成長
1995年以降また増え続けています
こういうのをささっと作ることができるのが
Pythonの強みですね
まとめ
Google Colabなどを使えば
Pythonをインストールしなくても
PC上からファイル操作を行えます
エクセルなどで開けない
ファイルが有るときは
是非Pythonを活用してみましょう。
それでは
それでは


コメントする