
先日、個人情報の入った
USBメモリの紛失事件が有りました
パスワードが気になっちゃって仕方ないです
解説動画はこちら
さて先日起きた事件ですが
USBメモリには
USBメモリの紛失事件が有りました
パスワードが気になっちゃって仕方ないです
解説動画はこちら
さて先日起きた事件ですが
尼崎市が、市民分約46万人分の個人情報が入った
USBメモリを紛失し
個人情報流出の恐れがあるという問題です。
個人情報流出の恐れがあるという問題です。
会見では、パスワードについて聞かれたときに
「英数字13桁のパスワードを設定している、
解読するのは難しいのかなと考えている」等と
返答してしまいました。
返答してしまいました。
USBメモリには
全市民の住民基本台帳データ46万517件
住民税に関する情報36万573件
生活保護や児童手当受給世帯の銀行口座情報合計7万6026件
非課税世帯等臨時特別給付金の対象世帯情報合計8万2716件
を保存していたそうです。
それでは「英数字13桁のパスワード」が
それでは「英数字13桁のパスワード」が
何通り有るのかを考えてみましょう。
パターン2:
英文字が大文字も小文字も使用されている場合
どちらも桁が多すぎてピンとこないですね
という感じになりました。
英数字13桁のパターンは
2000垓通り以上になります。
パターン1:
英文字が小文字だけor大文字だけ使用されている場合
こんな感じになりました。
やはり記号を用いると
グンと安全性が高まりますね
このUSBメモリであれば
6400年ほどは破られない可能性がありますが
辞書を用いた攻撃の場合
これよりももっと早く
解かれてしまう可能性があるので
油断は禁物ですね
パスワードを設定する場合は
文字種別も記号まで使い
16文字以上など桁数も多くしておくことを
おススメしたいと思います。
今回はここまでです
それでは。
文字種を用意してみよう
英小文字 aからzまでの26文字
英大文字 AからZまでの26文字
数字 0から9までの10文字
Python言語ではstringライブラリで用意できます。
import string suji = string.digits komoji = string.ascii_lowercase omoji = string.ascii_uppercase eiji = komoji + omoji eisuji = suji + eiji kigou = string.punctuation print(suji) print(komoji) print(omoji) print(eiji) print(eisuji) print(kigou)
0123456789
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
英数文字を含めた13桁のパスワードは
何通りでしょうか、計算してみましょう。
何通りでしょうか、計算してみましょう。
パターン1:
英文字が小文字だけor大文字だけ使用されている場合
英文字が小文字だけor大文字だけ使用されている場合
l1 = len(komoji + suji)
print(l1)
print('{:,}'.format(l1 ** 13))
print('{:e}'.format(l1 ** 13))36
170,581,728,179,578,208,256
1.705817e+20
パターン2:
英文字が大文字も小文字も使用されている場合
l2 = len(eisuji)
print(l2)
print('{:,}'.format(l2 ** 13))
print('{:e}'.format(l2 ** 13))62
200,028,539,268,669,788,905,472
2.000285e+23
どちらも桁が多すぎてピンとこないですね
1垓7058京1728兆1795億7820万8256
2000垓2853京9268兆6697億8890万5472
という感じになりました。
英数字13桁のパターンは
2000垓通り以上になります。
もしこれが仮に1秒間1兆回攻撃出来たとしたら
どれくらいで解けるでしょうか
計算してみましょう。
どれくらいで解けるでしょうか
計算してみましょう。
パターン1:
英文字が小文字だけor大文字だけ使用されている場合
l1 = len(komoji + suji)
times = l1 ** 13 // 1000000000000
print('{:,}秒'.format(times))
print('{:,}分'.format(times//60))
print('{:,}時間'.format(times//60//60))
print('{:,}日'.format(times//60//60//24))
print('{:,}年'.format(times//60//60//24//365))170,581,728秒
2,843,028分
47,383時間
1,974日
5年
パターン2:
英文字が大文字も小文字も使用されている場合
英数字13桁のパターン
2000垓通りを1秒間1兆回で
ブルートフォースアタックすると
6342年ほどで解読できる可能性があります。
ここからは、秒間1兆回で
色々な文字種と文字数で
どれくらい時間がかかるのか
計算してみましょう。
パターン2:
英文字が大文字も小文字も使用されている場合
l2 = len(eisuji)
times = l2 ** 13 // 1000000000000
print('{:,}秒'.format(times))
print('{:,}分'.format(times//60))
print('{:,}時間'.format(times//60//60))
print('{:,}日'.format(times/60//60//24))
print('{:,}年'.format(times//60//60//24//365))200,028,539,268秒
3,333,808,987分
55,563,483時間
2,315,145.0日
6,342年
英数字13桁のパターン
2000垓通りを1秒間1兆回で
ブルートフォースアタックすると
6342年ほどで解読できる可能性があります。
ここからは、秒間1兆回で
色々な文字種と文字数で
どれくらい時間がかかるのか
計算してみましょう。
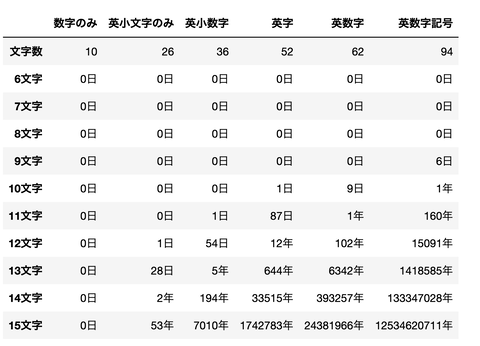
import pandas as pd
columns = ['数字のみ','英小文字のみ','英小数字','英字','英数字','英数字記号']
l1 = len(suji)
l2 = len(komoji)
l3 = len(komoji + suji)
l4 = len(eiji)
l5 = len(eiji + suji)
l6 = len(eiji + suji + kigou)
tmp_l = [l1,l2,l3,l4,l5,l6]
print(l1,l2,l3,l4,l5,l6)
df = pd.DataFrame(data = [tmp_l],columns=columns,index=['文字数'])
at = 10000 ** 3
day = 60*60*24
for i in range(6,16):
tmp = []
for l in tmp_l:
a = l ** i // at //day
if a>=365:
b = '{0}年'.format(a//365)
else:
b = '{0}日'.format(a)
tmp.append(b)
tmp_df = pd.DataFrame(data = [tmp],columns=columns,index=['{0}文字'.format(i)])
df = pd.concat([df,tmp_df],axis=0)
df
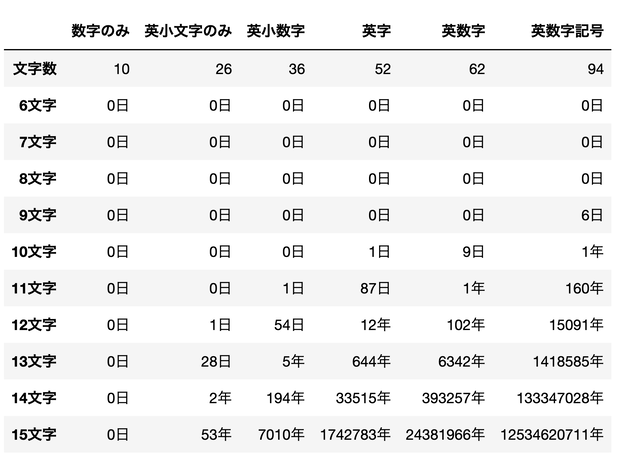
こんな感じになりました。
やはり記号を用いると
グンと安全性が高まりますね
このUSBメモリであれば
6400年ほどは破られない可能性がありますが
辞書を用いた攻撃の場合
これよりももっと早く
解かれてしまう可能性があるので
油断は禁物ですね
パスワードを設定する場合は
文字種別も記号まで使い
16文字以上など桁数も多くしておくことを
おススメしたいと思います。
今回はここまでです
それでは。


コメントする